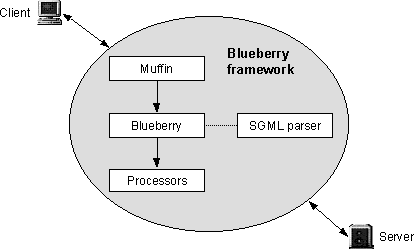
Figure 12. Blueberry architecture.
Client-side proxies | Master's thesis, May 2000 | |
<< Previous [ Blueberry ] Next >> |
Table of contents | |
Developed as a part of this thesis, Blueberry is a framework for processing the content of Web documents. Building on the proxy functionality of the extensible Muffin proxy, Blueberry provides an environment for swift and simple development of extension modules. This section also introduces BackLink, an example extension module. Blueberry is provided to visualise ideas about the implementation of client-side proxies, and not as an exercise in imaginative algorithms or a showcase for pretty programming. Hence, this section merely gives an overview of components and functionality. Readers interested in the details are invited to review the application, source-code and package documentation, available online [Blueberry 00].
As noted in the previous section, the extensible proxies Muffin and ByProxy do not provide an interface close to the content. Since an extensible proxy can contain modules with diverse functionality, a consistent and intuitive user interface is important. The first goal of Blueberry is to provide such an interface, a decision that rests on the assumption that content processing requires user interaction. A common look-and-feel for the proxy environment both helps and forces developers to provide user interaction that is consistent within the Blueberry environment. Consistent interaction helps users manage the configuration of multiple extension modules. Another assumption is that content processing produces additional information of interest to the user, and hence requires an interface that can display the information.
The second goal is to provide a solution that is both integrated with the client application and effectively client-independent. The choice of integration rather than separation follows from the decision to provide an interface. Since there is an interface, this should be close to the workspace of the user, visualising the relationship between processing and presentation. In the context of Web documents, the workspace is the browser. The common denominator of all browsers is HTML and Blueberry will provide a pure hypertext interface. The next choice is whether to display the interface in a separate browser window, a separate frame or embedded in the document. Separate browser windows have similar drawbacks as stand-alone application windows, and probably require Java or JavaScript to function properly. Inserting the interface in the original document is the easiest way to integration, but it destroys the intended layout of the document. What remains is to present the interface in a separate browser frame. This minimises the impact on the original document, makes it easy to distinguish the requested document from the interface, and it is still close to the user's working environment.
The third goal is to increase the productivity of third-party developers. Providing a ready-to-use interface is one way to do this, high-level access to the content is another. Muffin works with streams of high-level objects, and ByProxy works with byte-buffers. Both these approaches require extension modules to perform additional parsing to access the required content elements. The approach of Blueberry is to build a high-level data structure from the content stream, maintaining the internal hierarchy exhibited by HTML documents. Extension modules access the structure through object references, references that point directly to the type of content the modules are interested in. There is no need for additional parsing, and it is easy to navigate the nested hierarchy of each structure element. This should also prove beneficial to the overall performance of the application, but to some extent, the more demanding parse algorithm and the complex data structure lessen the gains.
As a side effect of these design choices, Blueberry is practically platform-independent, since it relies only on Java and HTML.
An obvious limitation is that Blueberry only supports processing of Web content. Request and reply headers, request redirection, and other details of HTTP communication are not accessible through Blueberry. However, the underlying Muffin proxy supplies this functionality. A Blueberry extension could choose to also implement the interfaces required by Muffin and register itself as a Muffin filter, thereby gaining access to these parts of the communication. Neither Blueberry nor Muffin supports non-HTTP communication.
The most notable deficiency is that Blueberry does not handle framesets or internal frames well. In the context of content processing, the content of framed documents is more interesting than the enclosing frameset document. At this point, there is no solution to the problem of treating framed documents as a single entity. In a best-case scenario, frame documents display correctly but will not be subject to processing. Following links in framed documents will probably cause problems, and nested framesets are never displayed correctly. Until this is resolved, behaviour regarding frames is unspecified and unstable.
Since Blueberry is a prototype implementation and not a production-quality release, there are inevitably other limitations. The functionality is not thoroughly tested, and there might be bugs and inconsistencies in the basic application and the programming interface for third-party developers. The code is not optimised for performance, although it should run well on most contemporary machines.
The Blueberry framework uses the extensible proxy Muffin to provide its own extensible environment. The major architectural components, depicted in figure 12, are Blueberry itself, an SGML parser and the programming interface for extension modules.
|
Figure 12. Blueberry architecture. |
Blueberry is an extension to the Muffin proxy. The Blueberry class, implementing Muffin's FilterFactory interface, the BlueberryFilter class that implements the HttpFilter and ReplyFilter interfaces, and various helper classes constitute an environment for content processing and user interaction. The basic tasks are extension handling, content parsing and user interface creation.
At initialisation, Blueberry loads all registered extension modules into memory. As a module is instantiated, it is queried for the element types it is interested in processing. This decides what the modules will get access to during the processing phase. Through the ReplyFilter interface, Blueberry intercepts replies from remote servers. Reply objects provided by Muffin give access to the raw content stream, which is processed by the SGML parser described below. The next step is to traverse the hierarchical tree structure created by the parser. For each HTML element in the structure, extensions that have registered interest in the element type are called upon to perform processing before the tree traversal continues.
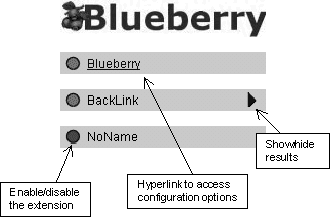 |
Figure 13. Blueberry user interface. |
When the requested document is processed, Blueberry transforms it to a frameset document; the left frame contains the user interface and the right frame the original document. The interface gives the user control over the available functionality. Individual modules can be enabled, disabled and configured (figure 13). Naturally, the interface is re-created for each requested document, and Blueberry collects the processing results of all enabled modules and presents them to the user. General configuration of Blueberry is also accessible from the interface frame; most important is the extension administration. Existing modules can be re-ordered, enabled, disabled or completely shut down, and new modules can be loaded and configured (figure 14). It is also possible to edit configuration files manually, but all functionality is accessible from within the client environment.
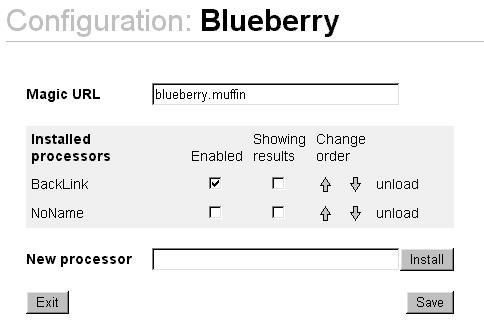 |
Figure 14. Blueberry configuration interface. |
The interface is quite large, as shown in figures 13 and 16. This could be a problem, especially with small screens. The assumption is that the information provided is valuable enough to justify this, but it might be necessary to reconsider this choice or at least make it possible to minimise the interface. In addition, the vertical frame might force users to scroll horizontally to view the main document. This is clearly an unwanted situation, and a future enhancement could be to let the user choose if the interface frame should be horizontal or vertical. Finally, Blueberry is not a transparent solution, at least where transparency is equal to invisibility. However, it is transparent in the sense that it integrates all its functionality within the browser environment, making it appear as part of the enclosing application.
Blueberry uses a simple protocol to support user interaction through hyperlinks, HTML forms, etc. All requests to a "magic URL" are intercepted through the HttpFilter interface of Muffin. By default, the magic URL is http://blueberry.muffin/, but it is user-definable. To decide what should happen, additional information is appended to the URL. This information has syntax similar to the queries created by the GET method of HTML forms. Blueberry parses the information and performs the desired action, either directly or by delegating it to the extension that initiated the interaction. This enables specific modules to provide interaction of their own, and it is also the method used to communicate directly with the Blueberry framework.
That Blueberry provides an environment for both processing and presentation can give third-party developers a sense of freedom, since they can focus entirely on the specific processing task performed by the extension. Other developers might feel that the framework is too prohibitive, since it forces extensions to behave in a certain way, especially regarding presentation of processing results. Indeed, it is limiting to demand that modules present their results as part of the enclosing Blueberry interface, but this is a conscious choice. It is necessary to circumscribe the freedom of individual developers to maintain a consistent interface.
The main vehicle for providing high-level abstraction and access to the content stream is a SGML parser (figure 15), responsible for transforming the content from a low-level byte-stream to a high-level hierarchical data structure.
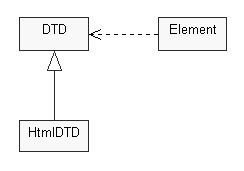 |
Figure 15. Overview class diagram of the SGML parser. |
The basic building block of the structure is an Element, encapsulating content elements and their associated attributes. An element can encapsulate standard mark-up elements, comments, character data, whitespace, and other types of content that appears in an SGML document. Since the structure is hierarchical, an element can also contain any number of other elements nested within its structure. The Element class provides methods for navigating the nested elements, finding specific elements, displaying elements, etc. It is also possible to create Element objects manually, for example by passing a string to the constructor or by using the element and attribute access methods.
While Element objects represent the actual content, a DTD object represents the data type definition, i.e. the grammar, applying to a certain document. The DTD enforces these rules by splitting the content into the components prescribed by the grammar, and by making sure nesting of elements is done according to the rules.
The abstract DTD class supplies all functionality for parsing and rule enforcement, making it easy to tailor the parser for other languages derived from SGML. A subclass must define nesting rules and characteristics of tags, comments and attributes in the specific mark-up language. The HtmlDTD class extends the DTD class to provide support for parsing HTML documents. At this point, there is no strict enforcement of the HTML data type definition, but rather a liberal parsing. The goal is to preserve the look of the original document, not to force it into syntactic correctness.
Although the structure created by the parser gives efficient access to individual elements, it makes progressive processing impossible. In a stream-based solution, already processed parts of the content can be progressively delivered to another proxy or to the user's client application before the processing is complete. In the high-level tree structure used here, the top-level elements are the last to be completed. This means that Blueberry must process the content completely before it can be restored to its original shape and released, which could have impact on the performance of proxy chains.
A module wishing to process content within the Blueberry framework must implement the BlueberryProcessor interface. This interface defines the methods that a module must provide, of which the most important are described here.
The handleElements method returns an array of strings containing the types of HTML elements the module wants to process. If a module registers interest in the anchor tag (A), the process method of the module is called every time an anchor appears in the content stream, with an Element instance and the address of the processed page as arguments.
When a document is completely processed, the hasDisplay method is called on all modules that are enabled and showing, to see if they have anything to display. If they have, Blueberry gathers the resulting Element objects by calling the display method of the modules, and displays the Elements as part of the user interface.
The methods for module configuration have a similar structure. If a module indicates that it is configurable, through the hasOptions method, Blueberry will display the name of the module as a hyperlink in the user interface. Clicking on the link will result in a call to the options method of the module, returning an Element object that Blueberry displays. Finally, the message method of the BlueberryProcessor interface is the medium for direct interaction between user and extension module. For example, a developer can use HTML forms to handle module configuration. When the user submits the form data, the module receives it through the message method. The BlueberryLink class encapsulates the specific format of these messages.
BackLink is an example Blueberry extension. For each visited page, it displays the "back-links" of that page, i.e. links to other Web pages that contain hyperlinks to the current document (figure 16). In its own right, BackLink would hardly qualify as a client-side proxy candidate. The only information it needs is the URL of the current document, and it could as easily be implemented as a browser plug-in. However, it takes advantage of the functionality of the Blueberry framework to gain access to content and to display results, visualising how easy it is to extend functionality without losing the consistent look-and-feel of the extensible framework.
 |
Figure 16. BackLink in action. |
BackLink consists of three classes. The BackLink class implements the BlueberryProcessor interface, acting as the link between the Blueberry framework and the BackLink functionality. The BackLinkDocument class is the abstract base class for queries to different search engines. It extends the Element class, inheriting the capability to build high-level data structures from the content. It provides BackLink with results to display, and it supports navigation of queries resulting in multiple-page replies. The Evreka class extends BackLinkDocument to provide specialised querying functionality. It handles queries to the online search engine Evreka (www.evreka.com), and parsing of query results. These classes can query remote search engines, parse replies and interact with the user, with less than 200 lines of (spacious) code.
If many people should use BackLink, it would probably have to use more of the content processing functionality provided by Blueberry. In the current version, it queries online search engines, parses the reply and displays the result. On a small scale, this is acceptable, but on a larger scale, there should probably be a dedicated BackLink server handling these queries. One way to maintain the server's database could be to let individual BackLink processors extract link information from visited pages and report the results to the server. In its simplest form and by using the processing functionality of Blueberry, implementing this function should not require more than a few lines of code. In this scenario, the proxy extension approach is better and more scaleable than browser plug-ins.
The Blueberry framework has visualised an approach not used by any of the other proxies examined in this work. The major difference is the close integration of user interface and client application. Now, all that remains is to examine the results of this and earlier sections, discuss them from a more general viewpoint and draw conclusions regarding the good and bad aspects of client-side proxies for content processing.
<< Previous [ Blueberry ] Next >> |
Table of contents | |