This report is an introduction and a state of the art study of the field of Natural Language Generation. An overview is made of the following subjects: Production of Natural Language of humans, Discourse analysis, Concepts in Discourse analysis, Different methodologies in Natural Language Generation, NLG and Natural Language Understanding, NLU. Further on are specific systems in NLG described, for example, explanations in Experts system, Query- and Answerings systems, Machine Translations systems and computer generated Natural Language descriptions of complex data. The report investigates both specific and general problems in Natural Language Understanding and Generation.
The two issues in NLG are: What to say and how to say it ? With other words What shall the computer select to say from the abundant knowledge base? What shall the discourse look like? How shall the computer say the information? How shall the syntactic structures look like? Which language and which words should it use?
One solution is to take the receiver of the text in account and to analyze the questions of the user. It also is possible to reason about the knowledge and beliefs of the user and hence reveal the level of knowledge of the receiver. One other problem in NLG is the lack of knowledge of how man generates an understandable text. This implies empirical studies of natural occuring texts to create applications of NLG on computers.
Den här rapporten är en introduktion och en "state of the art" studie i området textgenerering eller naturligtspråkgenerering, Natural Language Generation, NLG.
Med textgenerering menas produktion av text från en dator, med syfte att beskriva något sammanhang. Det kan vara diagnoser och förklaringar från ett expertsystem, en parafrasering från en formell specifikation med syfte att validera specifikationen, en börsrapport från börsdata, en väderrapport gjord från väderdata, en fråga från en dator till en användare eller sats från ett automatiskt översättningssystem. Det gemensamma med dessa är att en dator har skapat den textuella beskrivningen.
För att kunna göra dessa system krävs det kunskaper i forskningsområdet Artificiell Intelligens där lingvistik, psykologi, logik, filosofi och naturligtvis datorvetenskap ingår.
Två av problemställningarna i NLG är: Vad skall man säga och hur skall man säga det ? Med andra ord. Vad skall datorn välja att säga ifrån den stora kunskapsbasen? Hur skall diskursen se ut? Vilka syntaktiska strukturer skall användas? Vilket språk och vilkas ord skall användas?
När en text skall genereras måste mottagaren/datoranvändaren tas i beaktande. Att ta reda på vilken nivå mottagaren befinner sig på. Ett sätt är att ta reda på det är att analysera frågorna som användaren ställer. Ett annat är att resonera kring användarens kunskap och tro och på så sätt ta reda på vad användaren vet. Ett annat problem i NLG består i att det inte är känt hur en människa gör när hon skapar en text som är förståelig. Detta medför att det måste göras empiriska studier på naturligt förekommande texter för att kunna skapa förståeliga texter.
Det har gjorts ett antal tillämpningar i NLG, som tex förklaringar i expertsystem, fråge- och svarssystem, maskinöversättningssystem och avancerade verktyg som beskriver komplexa data i naturligt språk. Textgenerering kommer att vara en naturlig del i användandet av datorer i framtiden. Rapporter och beskrivningar kommer att framställas på många olika språk så fort man "trycker på knappen".
Den här rapporten är en introduktion och en "state of the art" studie i området textgenerering eller naturligtspråkgenerering, Natural Language Generation, NLG.
Rapporten behandlar produktion av naturligt språk av människor, diskursanalys, begreppen i diskursanalys, olika metodologier i textgenerering och naturligtspråkförståelse, Natural Language Understanding, NLU. Vidare beskrivs specifika och allmänna problem i NLG och NLU. Rapporten behandlar också specifika system i NLG, som t ex förklaringar i expertsystem, fråge- och svarssystem, maskinöversättningssystem och avancerade verktyg som beskriver komplexa data i naturligt språk.
Den här boken har sitt ursprung i en rapport som skrevs för SISU, Svenska Institutet för Systemutveckling 1991. Många intressenter hade hört av sig till SISU och önskat veta mera om naturligt språk och textgenerering. Därefter har boken uttökats, uppdaterats och förbättrats. De system som beskrivs i rapporten har behandlats ur textgenereringssynpunkt.
Rapporten består av fem olika delar.
Delarna är lagda i förekommande ordning i rapporten för att förhoppningsvis vara pedagogiska. Tanken är att om man läser från pärm till pärm får man en total introduktion i ämnet. Kapitlen är dock självständiga och går att läsa var för sig. Problemet blir kanske att en del termer som används in den praktiska delen är definierade i den teoretiska delen. Teorin hjälper till att förstå praktiken. Alla termer är definierade på slutet i kapitlet Ordförklaringar.
Det går t ex går bra att läsa kapitlet om naturligtspråkförståelse, Natural Language Understanding, NLU, och få en bra introduktion i databehandling av naturligt språk utan att läsa de andra kapitlen.
I rapportens första del beskrivs människans produktion av text och terminologin inom lingvistiken. Den andra delen behandlar den historiska utvecklingen som följs av en teoretisk del om själva textgenereringsområdet. Därefter behandlas den tekniska delen av olika textgenereringsmetodiker som följs av en del om NLU. I ett mer praktiskt avsnitt behandlas olika textgenereringssystem och slutligen visioner om framtiden.
Ordförklaringar inom textgenerering och naturligtspråkförståelse samt litteraturreferenser återfinns i slutet av rapporten.
Vi vill kunna kommunicera med datorerna på ett lätt sätt. En önskan är tex att kunna göra det med hjälp av naturligt språk, dvs på samma sätt som vi människor kommunicerar med varandra. För människan är det ofta mycket lättare att använda sig av sitt eget modersmål än av något annat naturligt språk eller ett formellt språk, som tex Pascal.
Människan har svårt att ta reda på den information som finns i datorerna, motsvarande svårigheter har datorerna att meddela oss denna information.
Behovet av att kommunicera med datorerna på ett lätt sätt har ökat radikalt med det ökade informationsutbytet mellan datorer och människor i det moderna samhället. Vi behöver få snabba rapporter, sammanställningar och förklaringar till olika skeenden i datorn och i samhället.
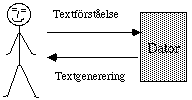
Att kommunicera innebär att datorn både förstår människans skrivna och talade språk, s k textförståelse, och att datorn kan tala och skriva till människan, s k textgenerering.
Den här rapporten kommer att handla om textgenerering med betoning på skriven text.
Figur 1. En dator kan förstå text men också skriva (generera) text.
Datorn "förstår" det människan säger och menar, dvs att låta människan tala och skriva till datorn på sitt språk istället för på datorns formella språk.
Datorn talar och skriver till människan på människans eget språk.
Textgenerering är ett forskningsområde, som är en underdisciplin till forskningen i Naturligtspråkbehandling, Natural Language Processing, NLP. Naturliga språk är de språk vi människor använder för att tala med varandra, t.ex svenska, engelska eller kinesiska, i motsats till artificiella - eller formella språk, dvs de av människan uppfunna språken, som logik, matematik eller programmeringsspråk.
Naturligtspråkbehandling är också ett forskningsområde inom Artificiell Intelligens (Artificial Intelligence, AI). Forskningsområdet har funnits i ungefär 30 år och uppkom i samband med att de första datorerna utvecklades i USA. AI är ett tvärvetenskapligt forskningsområde där disciplinerna datorvetenskap, filosofi, logik, lingvistik och psykologi ingår.
Ett av problemen i textförståelse, är att naturliga språksatser eller enstaka ord ofta innehåller tvetydigheter dvs en sats eller ett ord kan ha flera olika betydelser. En dator har inte människans världskunskap om hur saker och ting förhåller sig, om sammanhang, om tonfall, eller kanske ironi och mimik. Textgenerering har inte dessa problem eftersom datorn genererar text som förhoppningsvis är entydig. Svårigheten är att göra texten lättförståelig och lagom informativ. Texten måste också vara på rätt nivå för mottagaren. Textgenereringssystem är inte självständiga system utan de är integrerade med de system som de skall generera text för.
Utvecklingen av naturligtspråkgränssnitt i olika former har varit stor de senaste tio åren. Denna utveckling beror naturligtvis på den ökade datoranvändningen och de nya avancerande datorerna, men också på att programvaran blivit mer sofistikerad och att fler funktioner har blivit önskade. Dessutom har det tillkommit allt fler användare som inte har varit lika kunniga i datoranvändning som de allra första användarna, vilka ofta var tekniker.
En annan anledning är att flera olika naturliga språk har använts i och med den ökade internationaliseringen av marknaden. Behovet av snabba översättningar av affärskontrakt, manualer och bruksanvisningar etc har ökat. Datorerna har använts som stöd för att göra översättningar och hjälpa långsammare mänskliga översättare.
Textgenerering har funnits i tio år som eget forskningsområde med egna konferenser och workshops. Många trodde tidigare att textgenerering skulle vara lätt att göra och att det inte behövdes forskning inom området. Det visade sig dock vara mycket svårt att generera text och somliga anser att det är svårare än textförståelse. Detta beror på att man i början nöjde sig med ganska enkla meddelanden från datorn, men med mer komplicerade program som tex expertsystem, behövdes bättre förklaringar av resonemangen.
Den första textgenereringen bestod av sk canned text, hårdkodad text, som bestämdes av programmeraren i programmeringsögonblicket. Denna text var till god hjälp för användaren av programmet, men kunde inte ändras efteråt. Programmeraren kunde naturligtvis inte förutsäga allt som skulle behövas sägas till en användare och programmet hade inte heller någon kunskap i naturligt språk eller kunskap om vad det sa till användaren, (Shapiro 1987).
Det insågs även att den vanliga parafraserande texten direkt från expertsystemens regler inte var tillräckligt bra på att förklara resonemangen. Det behövdes en underliggande förklaringsmodell för att beskrivningarna skulle bli tillräckligt acceptabla, (Swartout 83). Sökmotor
Det har funnits och finns fortfarande ett antal problem med textgenerering från datorer.
När det gjordes försök att förbättra textgenereringen stötte man på stora teoretiska svårigheter dels med att anpassa texten till olika typer av användare som t ex experter eller noviser och dels med att göra texten tillräckligt informativ och förklarande.
Ett problem är att välja rätt mängd information och att organisera den så att användaren kan dra nytta av informationen. Ett annat problem är att representera betydelsen i texten som ska genereras. Kunskapsrepresentationsproblemet är gemensamt med forskningsområdet NLU.
Textgenerering kan betraktas som omvänd textförståelse. Istället för att datorn skall förstå en text som människan ger den, skall datorn generera en text som människan skall förstå.
Problemen i textgenerering är egentligen mycket större än i textförståelse. I textförståelse får människan uttrycka sig slarvigt och datorn, maskinen, ska anpassa sig och förstå. I textgenerering tolererar inte människan några slarviga texter om dessa är skapade av datorn. Det är svårt att ställa upp målet för textgenereringen: Vad är en bra text ? Hur skall en bra text se ut ? Det är svårt, eftersom det finns många sätt att utrycka en betydelse eller ett innehåll i en text.
En dålig text är t ex:
Internal error no 3421
Diskurs är den lingvistiska termen för en talad eller skriven text. En diskurs består av ett antal koherenta satser.
I den här rapporten skall vi koncentrera oss på generering av skriven text.
Detta kapitel går igenom människans produktion av diskurs samt de olika begrepp som används för att analysera denna diskurs.
En människa kommunicerar med hjälp av språket både genom att tala och skriva.
Det finns många stora skillnader mellan talat och skrivet språk.
Talat språk är flyktigt, snabbare och mindre planerat än skrivet språk, som är präntat och existerar ett tag. Grammatiken är enkel och saknar komplicerade konstruktioner. Talat språk eller talspråk är löst sammanhållet och fullt av ofullständiga satser. Upprepningar är vanliga i talspråk. Talat språk använder färre antal ord än skrivet språk. Talspråk är dock fyllt av små ord som talaren tillfogar men som inte har större betydelse för innehållet, ord som t ex: alltså, va, du vet, ähhh, umhh osv. Talspråk har fler dimensioner än skrivet språk, dimensioner såsom: intonation, slarvigt uttalade ord och kroppsspråk. Kroppsspråket säger kanske helt andra saker än talarens talade språk. Det är svårt att avgöra vad ett ord är i talat språk. Alla dessa dimensioner gör det svårt att analysera.
Skrivet språk är mer strikt grammatiskt och det använder fler ord än talat språk. I texten finns det skiljetecken som talar om när en sats slutar och när nästa tar vid, frågetecken som markerar fråga, citationstecken osv. Dessa skiljetecken tar bort en del av tvetydigheterna i skrivet språk och gör det lättare att analysera och att formalisera. Skrivet språk är mer explicit än talat språk.
För att kunna analysera talat språk krävs tre steg. Först en översättning från ljud till text och därefter en översättning från text till syntax, form, och slutligen en översättning från syntax till semantik, betydelsen, av det sagda. För att analysera skrivet språk behövs bara två steg. Först en översättning från text till syntax och därefter en översättning från syntax till semantiken av det skrivna.
Under en människas skrivprocess sker mycket av arbetet i hennes hjärna. Under skrivprocessen beslutas bla vad som skall skrivas. Detta kallas djupgenerering och sker genom att först ställa upp ett eller flera mål på vad som skall meddelas. Dessa mål delas upp i nya delmål. För att kunna fullfölja dessa mål måste en planering och idémässig organisation av uppgiften ske. Det måste t ex tas hänsyn till vilken/vilka mottagare som ska läsa texten. Organisationen realiseras eller ytgenereras därefter i en koherent och läsbar text. Ytgenereringen bestämmer syntaktiska strukturer och lexikala val.
Skrivprocessen sker inte i en linjär följd utan genom en ständig revidering av redan etablerade mål. Medan jag skriver detta så måste jag tänka på vilket budskap jag skall framföra, hur jag skall göra det, vilka mina läsare är och vilka ord jag skall använda. Människans process att bygga upp en diskurs vill man försöka åstadkomma i datorerna.
En intressant aspekt är att en människas passiva språkförståelse är snabb, medan hennes aktiva språkförståelse är relativt långsam. Att förstå en sats går lätt, men att formulera sig går långsamt. Med en dator är det ofta tvärtom. Den tar lång tid på sig på att parsa, att analysera en sats, men kan snabbt generera en sats.
För att kunna analysera en diskurs behövs ett antal begrepp. Dessa används både vid analys av en diskurs/text, (Brown 1987) och vid generering av en diskurs/text.
I denna del förklaras en del av diskursbegreppen och på slutet görs en diskursanalys på en text.
Koherens betyder sammanhängande eller följdriktig. Koherens är en term som mäter en texts tolkningsbarhet.
Det talas om relevans och om ansträngning för en mottagare att förstå en text. Hur bra är en text på att beskriva något dvs hur mycket arbete är det för någon att förstå texten eller att konceptualisera texten. En utgångspunkt är att en mottagare vill förstå den mest inkoherenta text och därför har en attityd till att den är koherent. På så sätt blir texten koherent. Många texter är koherenta om man har en tolerant attityd gentemot dem.
Det finns en klassisk sats från filosofin:
Färglösa gröna idéer sover ursinnigt.
Denna diskurs känns inte koherent, men den kan tolkas till något poetiskt i en dikt och då blir den genast något djupt, litterärt odödlig och betydelsefullt.
Om vi betraktar följande diskurs:
Jag tittade ut genom fönstret.
1) -> Ute lyste solen
2) -> Columbus upptäckte Amerika,
(Det var en tanke som slog mig)
Sats 1 gör hela diskursen koherent, medan sats 2 gör det svårt att tycka att diskursen känns koherent. En mottagare vill förstå en diskurs och han anstränger sig att finna koherensen. Detta görs genom att tänka sig en fortsättning (satsen inom parantes) eller genom ett antal inferenssteg för att länka ihop satserna.
Slutsatsen är att nästan alla diskurser är koherenta, om det finns en stor tolerans och fantasi.
Grice' samarbetsprinciper (Grice 1975) är ett antal konversationsprinciper som har utvecklats för att underlätta konversation, dessa principer brukar följas eller skall följas om man vill göra sig förstådd på ett effektivt sätt :
Var tydlig
Undvik tvetydigheter
Var kortfattad
Var metodisk
Observera att i ovanstående principer saknas något om sociala aspekter i språket som t ex smicker eller humor. Sociala aspekter på språket är viktigt för att människor skall kunna kommunicera med varandra.
Topik/Kommentar, (Topic/Comment ), är en metod att dela upp en diskurs i två delar.
Metoden används för att analysera vad en diskurs vill säga och för att generera nya diskurser.
Topik är det man skall tala om, dvs ämnet, medan kommentar är det man talar om, dvs kommentaren till ämnet. Detta gäller både inom en sats och inom en hel text, dvs en mängd av satser.
Topik delas ofta upp i satstopik och diskurstopik. Satstopik är topik inom satsen, dvs det satsen kommer att handla om. Diskurstopik är vad hela diskursen kommer att handla om.
Exempel på satstopik:
Kalle sprang efter bollen
Kalle är topik i satsen och sprang efter bollen är kommentar till topik
Fokus är det centrala i en diskurs. Fokus är det som betonas eller som skall framföras i diskursen. I en text blir fokus den röda tråden i resonemanget. För att finna fokus i en diskurs så kan man leta efter en bestämd beskrivning av fokus i satsen/satserna eller en pronomenreferens.
Exempel på fokus:
Kalle älskar Lisa, han älskar också Stina
Han refererar till Kalle och de är således koreferenter. Han är en pronomenreferens och Kalle är således fokus i satsen.
Linearisering innebär att en text läses och tolkas från vänster till höger och inte parallellt. Ordningen av satserna i diskursen är därför viktig. Hur skall startpunkten för en diskurs väljas ? Detta har stor betydelse för diskursens tolkning. Lineariseringsproblemet kan analyseras med tema/rema, (theme/rheme). Tema är i regel startpunkten och rema det som följer eller resten.
Pragmatik är vetenskapen om hur språket används och dess effekter på mottagaren.
Ett exempel på detta är satsen:
Vet du vad klockan är ?
Om svaret på denna fråga är: Ja , så kan pragmatiken tala om varför detta svar knappast är det önskade. Denna fråga används i ett annat sammanhang i praktiken än vad frågan säger semantiskt.
Koordinering kallas också samordning. Koordinering utelämnar redundanta lexikala objekt men bibehåller informationen, se även ellipsis och aggregering.
Ett exempel på koordinering är:
Johan och Lisa sprang efter bollen.
Ordet och är koordinator, men i andra fall kan även ordet eller vara koordinator.
Om satsen/satserna inte vore koordinerade skulle de se ut som följer
Johan sprang efter bollen.
Lisa sprang efter bollen.
Ellipsis definieras: Satser där utelämnade ord kan härledas av läsaren av texten, dock förekommer ingen koordinering.
Ett exempel på detta är:
John sprang efter bollen, liksom Lisa.
Ett exempel på en diskursanalys på ett textfragment tidigare i denna text:
1a) Naturligtspråkbehandling
1b) är också ett forskningsområde inom Artificiell Intelligens , AI.
2a) Forskningsområdet
2b) har funnits i ungefär 30 år och uppkom i samband med
att de första datorerna utvecklades i USA.
3a) AI
3b) är ett tvärvetenskapligt forskningsområde där disciplinerna
datorvetenskap, filosofi, logik, lingvistik och psykologi ingår.
Topik/kommentar:
1a) är huvudtopik i ovanstående diskurs. Satserna 2) och 3), kan betraktas som kommentarer till 1).
Diskursen kan också delas upp i ett antal fristående satser, där satserna 1) och 2), 3) är topik/kommentar strukturer.
Tema/Rema:
Tema är 1a) Naturligtspråkbehandling
Fokus:
Fokus i 1) forskningsområde inom Artificiell Intelligens .
Fokus i övriga satserna 2) och 3) är också forskningsområdet.
Koherens:
Koherensen störs om man vänder på ordningen på satserna 1), 2) och 3).
Om sats 3) sätts först, så ändras fokus till att handla om AI.
Om sats 2) sätts först, så blir sats 3) hängande i luften, eftersom den tidigare refererade tillbaka till sats 1). Dessutom ändras theme på alla satserna, eftersom det som sägs först är viktigast.
Sats 2) kan betraktas som tvetydig därför att det är svårt att se vad den refererar tillbaka till. Refererar sats 2) till Naturligtspråkbehandling eller Artificiell Intelligens ? Eller är det båda ? Jag tror att det är båda. (förf. anm.)
I det här kapitlet görs en genomgång av ett antal textgenereringsmetoder. Dessa metoder behandlar var för sig en del av de aspekter som är viktiga för att skapa en koherent och läsbar text.
I nästa kapitel skall motsatsen till textgenerering beskrivas nämligen naturligtspråkförståelse, NLU.
Textgeneringsmetoderna är nästan lika många som de system som använder sig av dem. Eftersom det finns så få system/metoder är det svårt att finna någon övergripande trend.
Men det går att urskilja följande komponenter, (McKeown 1988):
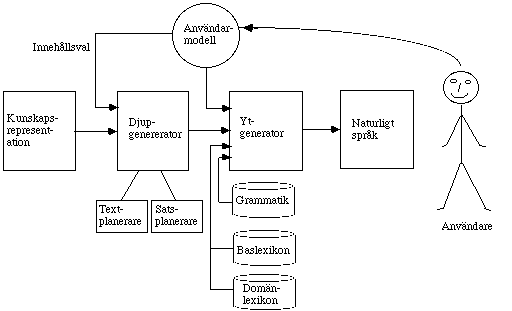
Figur 2. Ett generellt textgenereringssystem.
Ibland är det nödvändigt med växelverkan mellan djup- och ytgenereringskomponenten. Många system saknar en eller flera av ovanstående delar eller så har de helt andra lösningsansatser.
I textgenerering genereras allt från en sats, till texter bestående av ett antal satser och till hela sidor av text. I forskningsområdet finns en uppdelning mellan att generera en sats eller en hel text. En text består av en mängd satser som är koherenta.
Satsgenerering sker tex i ett fråge- och svarssystem där en fråga från en användare till en dator parafraseras tillbaka till användaren för att hon/han skall kunna kontrollera systemets tolkning. I satsgenerering är syntaxen och semantiken viktig. Vi människor är mycket känsliga för att syntaxen är korrekt, men om semantiken däremot är lite fel så försöker vi acceptera detta. Detta är lite märkligt med tanke på att betydelsen, semantiken, i en sats egentligen är viktigare än dess form, syntaxen.
Textgenerering behövs när ett mer komplicerat sammanhang skall beskrivas. I textgenerering är diskursens koherens det viktiga. Vi människor är relativt toleranta när det gäller koherens. Så länge satsernas syntax är korrekt, så försöker vi tolka texten till något meningsfullt.
En av de allra första textgenereringssystemen, bortsett från canned text systemen, genererade text direkt från semantiska nät (kunskapsrepresentationen), (Goldman 1975). Texten genererades med hjälp av ett antal regler som talade om vilka noder som skulle generereras först. Textgeneratorn sökte igenom nätet i en viss ordning och genererade texten. En text kunde bara uttryckas på ett sätt.
I en annan metod generaliserades processen till en algoritm som styrde textgenereringen. Algoritmen gav tillgång till olika delar av systemet och gjorde att de olika satserna kunde referera till varandra. Dessa system kunde inte anpassa sig till en viss typ av användare, utan var helt styrda av sin kunskapsrepresentation. Genereringsfaserna var helt oberoende av varandra. De flesta textgenereringssystem, som används idag, fungerar enligt ovanstående principer, enligt (Allen 1987).
Generering av naturligt språk brukar delas upp i två komponenter: djup- och ytgenerering. Djupgenerering är den del av textgenereringen där innehåll och organisation av texten bestäms, dvs Vad som skall sägas. Ytgenerering är den del av textgenereringen där själva realiserandet av texten, dess strukturella form och lexikala val sker, dvs Hur det skall sägas. Vissa forskare anser att dessa två delar inte är helt oberoende av varandra. Utdata från djupgenereringen (en text- eller satsplan) ges till ytgenereringen som skapar texten.
Djupgenereringen eller den strategiska komponenten är den del av genereringen där innehåll och organisation av texten bestäms. Det första målet i djupgenereringen är att bestämma vad texten skall uppnå. När detta mål är bestämt är det nödvändigt att samla ihop all information för att uppnå målet och ordna att innehållet i texten blir organiserat.
Vid djupgenereringen är det värdefullt att veta vad mottagaren av texten redan vet för att genereringen skall bli lagom informativ. I den moderna textgenereringen utgår man från människan och försöker göra texter som är anpassade för henne.
De fem nedan beskrivna ansatserna till djupgenerering är några av de ansatser som går att urskilja som olika fack inom djupgenereringen, (McKeown 1988). Diskursstrategier eller textplanering, Anpassning till användaren eller Användarmodellering, Satsplanering, Kunskapsrepresentationen, Planering och resonerande. Alla dessa delar behövs för att kunna skapa en bra text. Här nedan används de separat för sig. Ingen har ännu lyckats ta reda på alla uppgifter som ett textgenereringssystem skall kunna utföra.
Diskursstrategier är den vanligaste ansatsen till djupgenerering.
Ett system som använder sig av diskursstrategier är TEXT av McKeown (McKeown 1985a, 1985b). Hon studerade stora mängder text, som var skriven för tre olika syften: att definiera, att jämföra och att beskriva olika objekt. Från texterna fick McKeown fram fyra olika retoriska predikat, dvs basbegrepp för att uttrycka sig. Med hjälp av dessa fyra retoriska predikat definierade hon fyra retoriska schemata. Varje schema fungerar som en textplan och är uppbyggd som en graf. Varje schema kan svara på en eller flera typer av metafrågor om innehållet i en databas:
1) Hur är ett objekt definierat ?
2) Vad är skillnaden mellan två objekt ?
3) Beskriv tillgänglig information !
Svaren till dessa tre typer av frågor svarar självfallet de tre typer av texter som McKeown studerade.
Beroende på hur frågan ser ut väljs ett av scheman över hur en sådan fråga skall besvaras och hur objektet skall beskrivas i naturligt språk. De genererar ett svar som anses relevant för en viss given situation.
Först görs en semantisk begränsning av kunskapsbasen, denna begränsade kunskapsbas kallas för relevant kunskapspool. Poolen begränsas i sin tur av ett av de valda scheman. Schemat söks igenom av generatorn och fylls successivt på med information från den relevanta kunskapspoolen, samtidigt som generatorn växelverkar med en mekanism för att byta fokus. Functional Unification Grammar, (se nedan), används som textgenereringsgrammatik.
Systemet finns bl a implementerat för en databas som innehåller olika örlogsfartyg.
Här är ett exempel på en fråga som besvaras genom TEXT generatorn.
Frågan: What is a WHISKEY-SUBMARINE ?,
gör att schemat IDENTIFICATION väljs.
A whiskey is an underwater submarine with a PROPULSION_TYPE of DIESEL and a FLAG of RDOR. A submarine is classified as a whiskey if its CLASS is WHISKEY. All whiskies in the ONR database have REMARKS of 0, FUEL_CAPACITY of 200, FUEL_TYPE of DIESEL, IRCS of 0, MAXIMUM_OPERATING_DEPTH of 700, NORMAL_OPERATING_DEPTH of 100 and MAXIMUM_SUBMERGED_SPEED of 15.
Denna genererade text ser trevlig ut om man bortser från torftiga tabellnamn. TEXTsystemet kan dock inte dra några slutsatser från sin kunskapsbas.
En annan mer avancerad diskursstrategi är Manns och Thompsons Rhetorical Structure Theory, RST, (Mann 1988). RST skapades genom empirisk analys av ett antal texter. RST består av en mängd scheman som beskriver hur en textstruktur kan delas upp i mindre delar. RST bygger på relationer mellan olika delar av en text, som t ex mellan två satser i en text. Enligt Mann skall det räcka med 20 relationer för att beskriva en normal text. En liknande och besläktad teori är Hobbs' coherence relations, (Hobbs 1985,1990) se även (Dalianis 1992)
Varje schema definierar ett antal relationer. En relation länkar en kärna (nucleus) och en satellit (satellite). En kärna är ett centralt begrepp i en text, satellit är en annan del av texten som understödjer kärnan. Det finns en relation mellan varje satellit och kärna som visar hur varje satellit understödjer kärnan. Det kan också finnas relationer mellan två satelliter. En satellit kan i sin tur delas upp i en kärna och en satellit med hjälp av ett annat schema.Satser kan understödja varandra på olika sätt. Exempel på två av RST's retoriska relationer är exemplifierings- och generaliserings -relationen. Dessa två relationer är symmetriska med avseende på varandra. Manns antagande är att en text är koherent om alla dess delar kan rymmas i en övergripande relation.
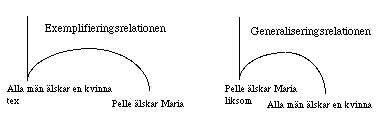
Figur 3. Vänder man på ovanstående exemplifieringsrelation, så erhålls en generaliserings relation.
Andra relationer är tex parallell, elaborering och kausal-relationerna.
Parallellrelationen binder ihop två eller flera satser som kan sägas oberoende
av deras inbördes ordning
Han skrev på sin bok , han drack kaffe och han satt på stolen
Elaboreringsrelationen är när den sats som följer går in på detalj på det från den föregående satsen.
Han skrev på sin bok, boken handlar om hur man behandlar naturligt språk.
Kausalrelationen är när den första satsen orsakar den andra satsen.
Han lyfte på luren. Telefonen slutade ringa.
RST och liknade teorier är på forskningsstadiet än så länge, men man hoppas kunna använda sig av tekniken på ett mer systematiskt sätt. (Exempel på användandet av RST se nedan, kapitlet Textgenereringssystem, Kritiserande system )
RST anses vara en mer generell teori än TEXT av McKeowns. TEXT har scheman som är statiska och fördefinierade medan RST använder sig av mindre scheman som är dynamiska och som skapar större variation i texten. Ett av problemen är dock att skapa en kontrollmekanism för genereringen i RST.
9.5.2. Satsplanering och Aggregering
En satsplanerare beslutar om hur en sats skall se ut. En sats kan ingå i en
diskurs som skapas av en textplanerare. En satsplan innehåller
information om satsens längd, aggregering, pronomenreferenser,
syntaktisk struktur etc (Dalianis 1999a, 1996b).En satsplan kan ingå i en textplan. Aggregering är ett intressant forskningområde
i gränsområdet mellan text- och satsplanering och hur dessa planerare
växelverkar med varandra.
Aggregering är en teknik om hur man tar bort redundant information från
en text (Dalianis 1999a, 1995a, 1996a,b,1997b]. Nedan ser vi först en oaggregerad
text som aggregeras och där till slut meningen i texen bli koncis och icke-redundant.
En enkel mening som: Ett lågtryck med centrum över Baltikum ger regn och
östliga vindar i både Göta- och Svealand. Innehåller en mängd
aggregeringar. Kanske mest uppenbart är att Göta- och Svealand lika gärna
kunde ha skrivits: Götaland och Svealand. För alla som kan svenska är
det också självklart att både Götaland och Svealand kommer
att få regn och östliga vindar. Men detta sägs inte uttryckligen,
utan genom en så kallad koordinering som markeras av ordet och.
Ytterligare en koordinering sker mellan regn och östliga vindar . Även
satsen om lågtrycket är inblandad i aggregeringen, genom att även
den gäller både vädret och området.
Med hjälp av signaleringsord, som både, respektive eller tillsammans,
kan man göra det tydligare och ta bort tvetydigheter när man aggregerar.
(Dalianis 1997a).
Med hjälp av signaleringsordet både så talar vi om att regn och
östliga vindar gäller för både Göta- och Svealand hade
det istället stått respektive Göta- och Svealand. Hade det inneburit
att det regnat i Götaland och blåst i Svealand.
I föregående exempel kan vi se att regn och östliga vindar är
subjekt- och predikataggregerad och både Göta- och Svealand är predikat
och ackusativobjektaggregerad.
Utifrån typerna går det att formulera ett antal olika regler för
aggregering. Totalt finns det ett tiotal aggregeringsregler men i praktiken används
bara två.
Om vi inte skulle ha aggregering alls så skulle ovanstående text se ut
så här: Ett lågtryck med centrum över Baltikum ger regn i Götaland.
Ett lågtryck med centrum över Baltikum ger östliga vindar i Götaland
Ett lågtryck med centrum över Baltikum ger regn i Svealand Ett lågtryck
med centrum över Baltikum ger östliga vindar i Svealand
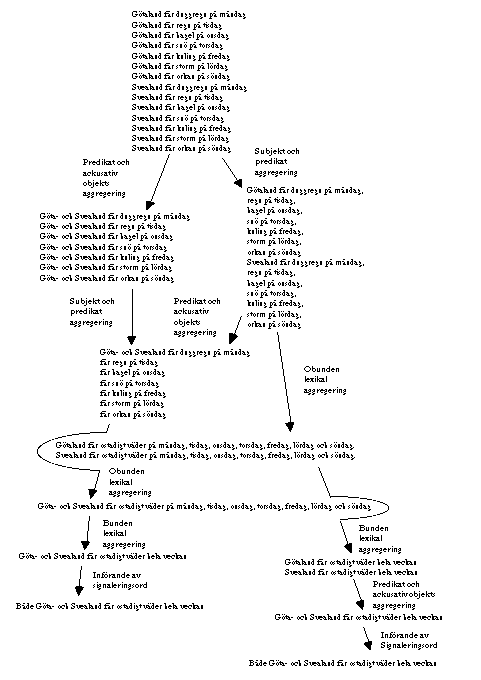
Figur 4
I figuren ovan har "måndag, tisdag, onsdag, torsdag, fredag, lördag
och söndag" ersatts med "hela veckan". Detta kallas bunden lexikal
aggregering och den ersätter ett antal ord med ett nytt ord som täcker
in de ersatta orden. Från den bundna lexikala aggregeringen är det möjligt
att gå tillbaka till den oaggregerade texten. Vi vet exakt vad "hela veckan"
innebär, (Dalianis 1997b).
Vidare ser vi i figuren ovan att "duggregn, regn, hagel, snö, kuling, storm
och orkan" ersatts med "ostadigt väder". Detta kallas obunden
lexikal aggregering och den ersätter ett antal ord med ett nytt ord som täcker
in de ersatta orden. Från den obundna lexikala aggregeringen är det ej
möjligt att gå tillbaka till den oaggregerade texten. Vi kan ej från
"ostadigt väder" exakt säga vilken typ eller typer av väder
det kommer att bli.
Anpassning till en användare innebär att textgeneringssystemet tar hänsyn till vem läsaren är, vilken nivå han/hon befinner sig på. Är det en expert eller är det en novis ? Systemen har en modell av användaren, (user model), som beskriver vilken typ av användare som skall ta emot texten.
En metod att avslöja användarens nivå är att analysera användarens fråga, då får man reda på vad han vet och inte vet (Appelt 1988). En annan metod är att studera föregående diskurs i en dialog. Om användaren ställer samma fråga två gånger så kan det betyda att han/hon inte förstod det föregående svaret.
En forskare vid namn C.Paris, (Paris 1985,1988) studerade två olika typer av uppslagsverk skrivna dels för vuxna och dels för barn. Hon upptäckte att texterna som var skrivna för vuxna beskriver alla delarna i objekten medan i texterna som var skrivna för barn beskriver funktionen av objekten. Texterna för barnen beskrev alla stegen i resonemangen och förklaringarna var övertydliga. Det innebär att vuxna får fakta presenterade för sig och att de sedan själva får dra sina slutsatser, medan barn måste få beskrivningar på varje objekts funktion. Utifrån dessa upptäckter skapade hon en strategi som går ut på att blanda de två sätten att beskriva objekt beroende på vad och hur mycket användaren vet.
TAILOR är en tillämpning på dessa teorier gjord av Paris (Paris 1988, McKeown 1988). TAILOR är en integrerad del till ett gränssnitt i naturligt språk som fungerar mot en komplex kunskapsbas. TAILOR får som indata dels en användarmodell och dels en förfrågan om att definiera ett objekt . Eftersom det finns för mycket information om varje objekt i databasen för att kunna göra en rimligt stor beskrivning i naturligt språk, så får TAILOR bestämma vilken information som skall tas med. Detta görs med hänsyn till användarmodellen. Systemet är dynamiskt så det kan blanda strategierna för att generera beskrivningar för ett brett spektrum av användare.
En fjärde ansats är att låta systemet resonera om användarens tro och kunskap för att kunna planera yttranden i naturligt språk. Ett sådant system är KAMP, Knowledge And Modalities Planner, av Appelt (Appelt 1985).
Systemet använder sig av modallogik, som är en utökad första ordningens predikatlogik. Predikatlogiken, (första ordningens logik), är ett begränsat logiskt språk som den tyske filosofen Frege uppfann på 1800-talet. I modallogik kan man även resonera med modaliteter som t ex att tro och att veta. KAMP representerar systemets och användarens tro och kunskap med ett axiomschema, en mängd alltid sanna satser. En teorembevisare får ta reda på om användaren har tillräcklig kunskap för att utföra en viss uppgift. En teorembevisare är en automatiserad process som kontrollerar om ett teorem är en logisk konsekvens av en mängd axiom.
En bieffekt av systemets användande av modallogik är att KAMP kan anpassa sig till om användaren verkar vara en novis eller expert. Appelt har utvecklat ett antal olika tekniker som eliminerar onödiga satser. Systemet kan om det vet att användaren inte vet en viss sak informera honom om det på samma gång som huvudmålet uppnås. Multipelmålen uppnås genom växelverkan mellan olika delmål på olika nivåer. Resultatet kommuniceras med en enda sats.
KAMP skiljer sig något från den vanliga uppdelningen mellan djup- och ytgenerering i textgenereringen därför att systemet växelverkar mellan de uppdelningarna.
Den första domänen KAMP utvecklades för, var ett expertsystem för underhåll och reparation där användaren var en novis. Appelt har koncentrerat sig på generering av enstaka satser istället för hela texter.
Ett exempel:
Målet är:
Att ta loss ett svänghjul
Systemet vet att användaren inte vet vilket verktyg han skall använda.
Delmålet till målet blir då att informera användaren att verktyget är en skiftnyckel som ligger på bordet.
För att uppnå dessa två mål skulle två satser behövas:
Var god och ta loss svänghjulet med skiftnyckeln.
Skiftnyckeln ligger på bordet.
Men det går att slå ihop dessa två mål till ett:
Var god och ta loss svänghjulet med skiftnyckeln som ligger på bordet
En femte ansats är att från början anpassa kunskaps- eller databasen för generering i naturligt språk och speciellt för förklaringar om hur systemet är uppbyggt. (Se nedan avsnittet om MYCIN)
För att ett system skall ge bra förklaringar krävs enligt (McKeown 1988)
1) Rättfärdigande och bevisning av sina resonemang.
2) Beskrivning av generella problemlösningsstrategier.
3) Definition av termerna som används i resonemangen.
Dessa tre punkter behövs inte för att ett expertsystem skall fungera och ge rätt svar på olika problem. Däremot behövs dessa tre punkter för att få bra förklaringar och förståelse i hur expertsystemet resonerar och då måste detta designas separat från själva expertsystemets problemlösningsmekanism.
XPLAIN, (se nedan) är ett system som uppfyller punkterna 1) o 2) och Explainable Expert System (EES), (Neches 1985) uppfyller punkterna 1), 2) o 3).
Det är mycket svårt att installera bra förklaringsfunktioner till ett redan existerande expertsystem.
XPLAIN är ett system utvecklat av W.R Swartout, (Swartout 1983). XPLAIN löser problemet med de torftiga förklaringarna i expertsystemen. För att göra ett expertsystem måste en eller flera experter intervjuas. Experten får tala om vad hon/han vet, alla slutsatser med rättfärdigande och förklaringar. När sedan expertsystemet utvecklats så behövs inte all denna information för funktionen därför försvinner nästan all bevisning och rättfärdigande av olika slutsatser. Detta beror på att dessa inte behövs för själva expertsystemets funktion. När en förklaring på en problemlösning önskas så fås en parafrasering på reglerna men ingen egentlig förklaring. XPLAIN kringgår det här problemet genom att den själv skriver (automatiskt programmerar) expertsystemet.
XPLAIN skapar från en domänmodell och domänprinciper hela expertsystemet med slutsatsdragningar och förklaringar samt en förfiningsstruktur, (refinement structure). Domänmodellen eller den kausala modellen beskriver de viktiga relationerna i domänen och deras inbördes orsak och verkan. Domänprinciperna är den procedurella kunskapen eller problemlösningsstrategin om hur ett problem ska lösas. Förfiningsstrukturen ger förklaringsfunktionerna tillgång till beslut som gjordes när expertsystemet skapades. Förbättringarna av förklaringarna bygger mer på tillgången på strukturen än på att själva språkgeneratorn är mer avancerad.
XPLAIN kan ge övergripande förklaringar till vad den försöker uppnå samt mera detaljerade förklaringar till ett visst mål. Skulle användaren fortfarande inte förstå förklarar XPLAIN ytterligare detaljerat.
Ytgenereringskomponenten måste ha en grammatik, dvs den mängd syntaxregler, som beskriver språkets syntaktiska struktur samt ett lexikon som beskriver ordens böjningsmönster. Det mesta av den tidigare forskningen i textgenerering har skett inom det här området.
Ytgenereringen eller den taktiska komponenten är själva realiserandet av texten, dess strukturella form och lexikala val. Ytgeneratorn får ta emot en intern struktur, t ex logisk form från djupgeneratorn eller det organiserade innehållet av den slutliga texten, och därefter får ytgeneratorn välja ord och syntaktisk struktur för att realisera budskapet i t ex aktiv form, t ex Pelle älskar Lisa, eller passiv form, t ex Lisa älskas av Pelle. Med aktiv eller passiv form betonas olika saker. Ytgenerering kräver stor kunskap om hur olika lingvistiska strukturer har olika lingvistiska effekter.
Ett mål med de nya grammatikformalismerna för textgenerering är att grammatiken skall kunna växelverka med djupgeneringsfasen. Att valen av syntaktisk struktur ska påverka själva djupgenereringen.
En skillnad mellan textgenereringsgrammatiker jämfört med parsningsgrammatiker eller analysgrammatiker är att i textgenereringsgrammatiker måste den funktionella strukturen först bestämmas. Betrakta en textgenerator som bestående av två delar: en djup- och en ytgenerator. Först planeras budskapets funktion eller verkan i djupgeneratorn och därefter bestäms i den syntaktiska strukturen i ytgeneratorn som skall realisera funktionen.
I den lexikala komponenten sker valet av ord. Valet av ord beror på den syntaktiska strukturen på samma sätt som den syntaktiska strukturen beror på valet av ord.
Ett problem med naturligt språk system är att de måste anpassas till varje ny domän. Eftersom lexikonet inte innehåller alla nya ord som behöver användas måste de läggas till. Detta är en riktig flaskhals i tillämpningen av naturligt språk system.
Den lexikala komponenten anropas ibland före den syntaktiska strukturens skapande och ibland efter. Dessutom har vi problemet med vilka ord som skall användas. Det finns ansatser där man valt att ha hela fraser, s k idiom, t ex ordspråk, färdiga att generera. Fasta idiom är svåra att skapa med en grammatik eftersom de har en helt annan betydelse än själva sammansättningen av orden som ingår i dem. Satsen Hur står det till ? är ett idiom.
Valet av ord i ytgenereringen kan ibland bero på typen av användare. Vilket kan i sin tur påverka djupgenereringen så att den behöver göras om. Det innebär att djup- och ytgenerering inte kan separeras.
Inom NLP så är det idag "hett" att använda sig av ontologier för att bygga lexikon. Ontologier är hierarkiskt organiserade statiska strukturer eller taxonomier med begrepp. Ontologier behöver inte vara domänspecifika utan snarare tvärtom de skall innehålla mycket generell kunskap. Det har också blivit vanligt att datorbaserade lexikon inte bara är alfabetiskt ordnade utan också enligt ontologiprincipen i hierarkiska grupper med gemensamma begrepp. Ett exempel på en sådan ontologi är WordNet en annan äldre ontologi är CYC, se även avsnittet nedan om CYC-projektet.
Lexikon kopplade till ontologier har sitt ursprung i slutet på 80-talet. i det sk CYC-projektet (Lenat 1987). Lenat gjorde en analogi med människans utvecklings- och lärandefas. När människan är riktigt ung får hon kunskap utan att fråga efter den. Därefter blir hon intresserad och börjar kommunicera med omgivningen för att få reda på mer. Till slut vet människan mer än alla andra (idealt sett) och hon upphör då att tala med dessa. Hon börjar upptäcka ny kunskap från det hon redan vet.
Hypotesen var att för att ett system ska bli intelligent så krävs det att den hade en stor bakgrundskunskap. Därför skulle man mata in all kunskap som fanns i Encylopedia Britanica i ett datorsystem. Detta skulle ta 10 år att göra. Hypotesen var att efter 4 års inmatande så kommer systemet själv att fråga efter information. Efter 10 år kommer systemet veta mer än alla människor tillsammans. Då kommer systemet att upptäcka ny okänd kunskap från det systemet redan vet. Det blev inget självlärande system men det blev ontologier som återanvänds och som byggs upp till större och större kunskapsbaser.
Textgrammatik kallas även för diskursgrammatik. Diskursgrammatiken består bl a av olika diskursrelationerna såsom t ex topik/kommentar, tema/rema och fokus. Diskursgrammatik talar om hur de olika satserna kan kombineras med hänsyn till diskursrelationerna. I en diskurs begränsar den första satsen den andra satsen och den andra satsen begränsar i sin tur tredje satsen osv.
Satsen Hur står det till ? kan spela olika roll beroende på om den används i början av en diskurs eller mitt i diskursen. I början av diskursen fungerar satsen som ett idiom och är bara en hälsning. Inne i diskursen har satsen betydelsen av ordens sammansatta betydelse.
Används en avancerad textgrammatik flyttas större delen av arbetet till ytgenereringskomponenten. Används en vanlig satsgrammatik, en grammatik som genererar endast satser, får djupgenereringskomponenten göra en större del av arbetet. Man kan säga att det inte finns rena textgrammatiker utan man använder sig en serie av processer (i djupgenereringen) som skapar texten.Processerna kan vara innehållsval, användarmodellering, textplanering och satsplanering där tex aggregering ingår.
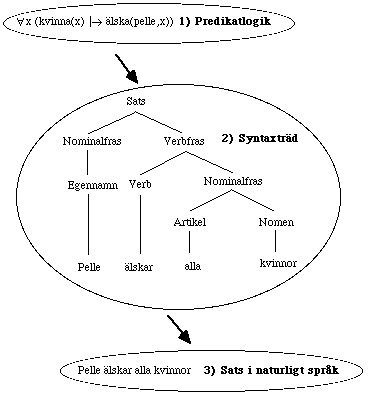
Figur 5. Generering från predikatlogik till syntaxträd och slutligen till en sats i naturligt språk.
Ytgenerering kan betraktas som omvänd syntaxanalys, omvänd parsning. (Se nedan i kapitlet Naturligtspråkförståelse). Vanlig parsning av en sats innebär att datorn gör en syntaxanalys av satsen, tar ut satsdelar och bygger upp ett syntaxträd, på samma sätt kan man göra en omvänd parsning av syntaxträdet och få tillbaka motsvarande sats, sk textgenerering. En inriktning är att två-riktade (bi-directional) eller reversibla grammatiker. En sådan grammatik kan användas både för parsing och för generering. Ett exempel på en reversibel grammatikformalism är Functional Unification Grammar, FUG.
I Prolog är det lämpligt att använda sig av en DCG (Definite Clause Grammar) grammatik, En DCG grammatik kan användas både som generator och parser, dock får man skriva två skilda grammatiker för de olika uppgifterna.
Grammatikutveckling är dyrbart och tidsödande. Om det gick att minska kostnaden för utvecklingen skulle mycket vara vunnet. Reversibla grammatiker kan tex utvecklas först för parsning och därefter kan grammatiken vändas och köras baklänges för generering. Därför är reversibla grammatiker önskvärda, de går att använda åt båda hållen.
De allra första textgenereringsgrammatikerna på 70-talet var ATN-grammatiker, (Augmented Transition Network-grammar), och de var representerade som grafer som genererade satserna direkt från kunskapsrepresentationen, (Allen 1987).
Systemiska grammatiker (Systemic grammars), främst Halliday`s,(McKeown 1988) är en grammatikformalism anpassad för textgenerering i och med att den kan växelverka mellan syntaktiska, semantiska och pragmatiska delar av systemet för att göra syntaktiska val. Dessa olika delar begränsar möjligheterna för hur satsen skall se ut. Varje del i grammatiken ger en valmöjlighet som till slut ger den slutliga satsens struktur.
Functional Unification Grammar av Kay, (McKeown 88), är en reversibel grammatik och ett försök att se till språkets funktion och användningsområden framför dess syntaktiska struktur. Representation av innehåll, struktur och lexikala delar är enhetlig. De olika delarna är modulära, dvs de går att ändra var för sig.
För att datorerna skall förstå människans språk, t ex en fråga eller ett påstående från en människa, måste datorerna göra en analys av det som sägs. Detta görs genom en syntaktisk och en semantisk analys av satsen.
I detta kapitel beskrivs de olika stegen i naturligtspråkförståelse, Natural Language Understanding, NLU.
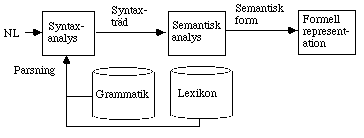
Figur 6. Syntaktisk och semantisk analys av en sats i naturligt språk, Natural Language, NL.
En syntaktisk och semantisk analys av en sats i naturligt språk börjar med att först göra en parsning. En parsning av en sats innebär att en parser i en dator gör en syntaxanalys av satsen, tar ut satsdelar och bygger upp ett syntaxträd. Resultatet av parsningen, syntaxträdet, översätts av en semantisk analysator till en formell representation som står för själva semantiken, dvs betydelsen av satsen.
En sats kan ha flera olika syntaktiska strukturer dvs den kan vara tvetydig. Satsen kan ha flera olika betydelser. Den formella representation av satsen skall dock vara entydig. En formell representation för varje betydelse.
NLU och NLG har två starka knutpunkter:
1) Samma grammatik och lexikon kan ofta användas av båda systemen.
2) Den formella representationen av naturligt språk kan vara samma för båda systemen.
En grammatik är den mängd syntaxregler som beskriver hur ett språk är uppbyggt och och ett lexikon vilka ord som finns. Ett språks syntaxregler eller grammatik bestämmer i vilken ordning orden skall komma. En grammatik kan beskriva olika typer av språk. En reguljär grammatik kan endast beskriva ett enklare språk, en kontextfri grammatik kan beskriva ett programmeringsspråk eller ett begränsat naturligt språk, en kontextsensitiv grammatik kan beskriva ett naturligt språk.
En grammatik kan betraktas som en axiommängd, en mängd alltid sanna regler. Satsen som skall parsas motsvarar teoremet som skall bevisas i denna axiommängd. Programmeringsspråket Prolog kan ses som en teorembevisare och därför är Prolog ett lämpligt språk att använda för syntaxanalys.
En grammatik kan skrivas direkt i Prolog vilket underlättar programmeringsarbetet. Prologprogrammet kan analysera satsen och avgöra om den är grammatiskt korrekt. Det är även möjligt att generera alla möjliga satser som grammatiken beskriver, s k satsgenerering. Allt detta sker med samma program skrivet i Prolog.
En parsning av en sats innebär att ett parserprogram och en grammatik i en dator gör en syntaxanalys av satsen, dvs tar ut satsdelar och bygger upp ett syntaxträd. En parser är en grammatik och ett program.
Parsning av sats är en flaskhals i NLU eftersom det behövs en stor grammatik med många grammatikregler och lämpliga ord för att beskriva ett naturligt språk. En parsning medför att en mycket stor sökrymd måste genomsökas. Detta måste göras på ett effektivt sätt genom olika parsningsmetoder. Exempel på parsningsmetoder är t ex top down, bottom up, och chart parsning.
En parser kan under analysen av en sats även generera ett syntaxträd.
Parsning kan bestå av flera olika delar. Morfologisk analys eller ordanalys,
vilket ger alla tolkningar av ett ords funktion. Taggdisambiguering (kallas slarvigt
för taggning) som ger en tolkning av ett ords funktion och slutligen den syntaktiska
parsningen som bygger upp syntaxträdet.
Resultatet av taggningen kan ge ett index över alla betydelsebärande ord
eller så kallade nyckelord. Dessa nyckelord beskriver
innehållet i den analyserade texten.
Semantik är betydelsen, av det sagda som måste analyseras och inte bara ordens inbördes ordning, syntaxen.
Resultatet av parsningen det s k syntaxträdet, översätts med en semantisk analysator t ex till predikatlogik eller någon annan formell representation. Satsen har då formaliserats. Därefter görs en tolkning av representationen och då erhålles satsens betydelse, semantik. En tolkning är en jämförelse mellan satsens formella struktur och den verkliga världen. Det går då att avgöra om satsen är sann eller falsk. Den formella representationen går även att använda för att generera naturligt språk. Genom att köra semantikproceduren och parsern "baklänges" genereras naturligt språk, s k textgenerering.
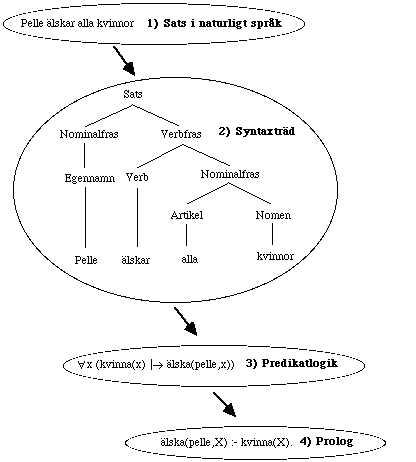
Figur 7. Parsning av en naturligt språk sats, och översättning av parsningsresultatet, syntaxträdet till första ordningens predikatlogik, som därefter översätts till Prolog, som är ett språk som datorn förstår.
Idag forskas det fortfarande på att identifiera semantiken i naturligt språk och representera det i ett formellt språk eller ett sk interlingua, en sorts språkoberoende representation.
Eftersom naturligt språk har tvetydiga satser är det nödvändigt att kunna representera dessa på ett entydigt sätt. En vanlig representation för att lösa problemet med tvetydigheter i NL är första ordningens predikatlogik. Varje betydelse eller tolkning av satsen representeras med en formel i första ordningens predikatlogik. Genom att översätta det naturliga språket till predikatlogik och sedan översätta predikatlogiken till t ex Prolog som är ett programmeringsspråk och som datorn förstår, så kan analysen utföras maskinellt, (Pereira 1987).
Några andra äldre representationsformer med rötter i AI-världen är t ex semantiska nät,frames och scripts osv .Dessa är dock inte tillräckligt kraftfulla för att uttrycka semantiken i alla satser i naturligt språk. Därför har det gjorts försök att finna kraftfullare moderna semantiska teorier. Tre av dessa teorier är Montaguegrammatiken, Situationssemantiken och Diskursrepresentationsteorin.
Montaguegrammatiken, (Montaguesemantiken) (Dowty 1987), är en teori som kom i början på 70-talet. Montaguegrammatiken bygger på att det inte finns några teoretiska skillnader mellan formella och naturliga språk. I Montaguegrammatiken gäller ett ett-till-ett förhållande mellan syntaktiska och semantiska regler samt den s k kompositionalitetsprincipen eller Freges princip, dvs sanningen av helheten beror på sanningsvärdet av delarna.
En analys av en sats går ut på att studera satsens syntaktiska struktur och till varje strukturdel försöka applicera motsvarande semantiska regel. Resultatet av analysen är en formell semantisk struktur på hela satsen.
Montaguegrammatikens semantiska regler använder sig av ett helt batteri av mängdlära, predikatlogik, modallogik, lambdakalkyl, typteori osv. Tolkningen av Montaguegrammatiken sker i en möjligvärldsemantik. Tolkningen kräver att möjliga världar införs. En möjlig värld är ett tillstånd vilket kan vara eller får vara möjlig men kanske inte är det just nu. En tolkning av en sats finns i form av en av dessa världar.
Den semantiska strukturen tolkas genom att de olika delarna tilldelas sanningsvärdena sant eller falskt och på så sätt erhålls tolkningen dvs om satsen är sann eller falsk i förhållande till vad som är känt om just den värld som tolkningen görs i. Satsen Katten sover är sann i en värld där det finns en speciell katt, en instans av en katt, katten Misse, som sover, men falsk i de världar där det inte finns någon katt som sover.
En delmängd av formalismen är enkel att tillämpa. Denna del kan dock inte beskriva allt i naturligt språk. Montaguegrammatiken används idag av de flesta NLU-systemen, tex HSQL (se nedan avsnittet om HSQL).
Den andra teorin är Situationssemantiken, (Barwise 1981, Fenstad 1987), som kom i början på 80-talet och har utvecklats mycket sedan dess. Situationssemantiken formaliserar naturligt språk på ett helt annat sätt än i Montaguegrammatiken. Genom att utgå från naturligt språk och de situationer där naturligt språk används formaliseras språket till ett sk situationsschema. Detta görs genom att världen betraktas och från detta byggs det upp olika relationer mellan olika situationer. Exempel på sådana situationer är: yttrandesituationen: Var och hur sägs satsen, beskriven situation: Vilken situation beskriver satsen, bakgrundssituationen:. Hur är situationen där satsen sägs osv.
Situationssemantiken är inte bunden till syntax för att analysera en sats eller en text. Istället kan en lexikal- eller fonetisk analys göras av satsen vilket leder till en formell struktur, ett s k situationsschema. Detta schema kan därefter tolkas. Situationsschemat innehåller så mycket information som man önskar lägga in. Alla situationer tillsammans ger mera information om satsen. Varje situation har en del av sanningen, eller ger en tolkning av en sats. Tolkningen går till på så sätt att att man undersöker de olika situationerna och ser om de har relationer till varandra som överensstämmer med situationsschemat. En situation ger en partiell tolkning av en sats. Alla situationer tillsammans begränsar tolkningen av satsen till den "rätta".
Situationssemantiken anses vara mer kraftfull än Montaguesemantiken, men svårare att tillämpa. Den har inte funnits i mer än tio år och är inte färdigutvecklad ännu. Därför finns det inte många tillämpningar som använder sig av situationssemantiken.
En tillämpning som dock använder sig av Situationssemantik är ett gränssnitt i naturligt språk utvecklat i Prolog, (Vestre 1988). Frågor representeras som en speciell form av ofullständiga situationsscheman, som växelverkar med en databas för att besvaras, dvs de fylls i och blir fullständiga situationsscheman.
Den tredje teorin är Discourse Representation Structures, DRS och Discourse Representation Theory, DRT, (Kamp 1990). DRT är en teori som formaliserar hela texter eller grupper av satser medan vanlig logisk semantik formaliserar en sats i taget. DRT är en partiell teori som tar upp delarna av en text som tillsammans bildar helheten. DRT analyserar varje textfragment var för sig som tillsammans bildar helheten. DRT har s k inbäddbarhet mellan olika delar av den formella representationen.
DRT har vidare en bra metod att korsreferera mellan olika satser med så kallade referensmarkerare, emedan det i vanlig logisk semantik endast är möjligt att representera allt i en formel. Olika delar av strukturerna kan bäddas in i varandra. Dessa är oberoende av varandra men när de tolkas uppstår helheten. I detta liknar DRT och Situationssemantiken varandra.
Sanning i DRT har med att finna individer i diskursen som korresponderar till referensmarkerarna i den formella representationen. Egennamn eller individer spelar en stor roll i att förankra DRT till världen.
Tillämpningarna av DRT är fåtaliga men en är: ACORD som är ett fråge- och svarssystem till en kunskapsbas. Systemet har en representationsformalism som bygger på DRT, (Kohl 1990). ACORD använder sig av naturligt språk både för frågor från användaren och svar till användaren.
Detta kapitel går igenom ett litet urval på tillämpningar av de tidigare beskrivna teorierna. Några typiska system och de texter de producerar redovisas. Ändamålet med beskrivningarna av systemen är att visa på den praktiska tillämpbarheten på teorierna samt demonstrera möjliga användningsområden. Tillämpningarna som beskrivs är textgenererings- och parafraseringsystem som används i en rad olika datorsystem bla fråge- och svarssystem, förklaringar i expertsystem, avancerande system för dokumentframställning, verktyg och stöd både för att skapa och beskriva komplexa databaser, instruktioner från datorsystem och maskinöversättningssystem.
Fråge- och svarssystem kallas även Query and Answering systems, Q&A. Med detta avses ett gränssnitt i naturligt språk mellan dator, databas och användare. En användare kan ställa frågor till datorn på sitt eget språk istället för att använda sig av en formell och svårförståelig frågenotation eller formellt språk. Datorn analyserar och översätter användarens fråga i naturligt språk till den formella notationen som sedan skickas till databasen och frågan besvaras, svaret översätts till naturligt språk och returneras till användaren. Detta betyder att en användare inte behöver bry sig om hur information i databasen är lagrad och att hon/han inte behöver lära sig en formell notation för att få ut information från en databas.
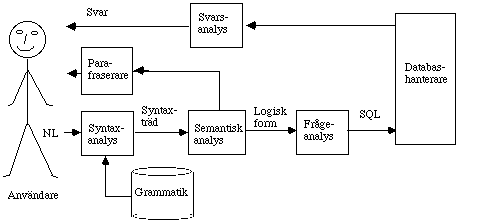
Figur 8. Traditionellt fråge- och svarssystem och dess uppbyggnad
En användare matar in en naturligt språksats till en dator. Denna sats står för något kommando eller en fråga. Datorn gör en syntaktisk och semantisk analys av satsen och översätter därefter satsen till ett internt formellt språk som datorn förstår. Denna interna representation representerar satsens semantik eller betydelse. Om satsen är tvetydig kan det ge upphov flera olika interna formella representationer av satsen.
Därefter parafraserar datorn den interna representation eller representationerna tillbaka till naturligt språk. Datorn gör en tolkning av den inmatade satsen och parafraserar tillbaka den till användaren. Syftet med parafraseringen är att kontrollera med användaren om datorsystemet har förstått satsen korrekt.
Om det är så att användarens fråga har många tolkningar kan han välja den som han tycker överensstämmer med det han menade och låta den gå vidare i datorsystemet.
Satsens formella representation skickas vidare i fråge- och svarssystemet och översätts till t ex SQL, Structured Query Language, som skickas till databasen. Svaret hämtas upp och denna tabellinformation översätts till naturligt språk som skickas till användaren. Användaren har kommunicerat helt och hållet med delar av sitt modersmål; det naturliga språk hon/han behärskar bäst.
Hjälpsystem för Structurered Query Language, HSQL, är ett prototypsystem utvecklat i samarbete mellan de nordiska länderna och finansierat av Nordiska Ministerrådet. Forskare har deltagit från SISU, Svenska Institutet för Systemutveckling i Sverige, från Runit i Norge, från VTT/TIK i Finland, och från AXION i Danmark, (Amble 1990).
I HSQL finns i tre versioner en svensk, en norsk och en dansk. Den fungerar som så att en fråga i ställs i naturligt språk till HSQL och översätts därefter till SQL och skickas till databasen och slutligen får man sitt svar.
Om den ställda frågan är tvetydig så returneras dess olika tolkningar i naturligt språk, en s k parafrasering. Det finns då möjlighet att välja den tolkning som anses vara den rätta, annars måste användaren omformulera sig.
Parafraseraren utgår ifrån de tidigare genererade SQL satserna, när den parafraserar tillbaka till naturligt språk. En DCG-grammatik parsar SQL-satsen som översätts dels till ett parseträd och dels till attribut/värde-matriser som inte har ifyllda värden. Dessa fylls på under den semantiska tolkningen från kunskapsbasen. Att värdena inte är ifyllda beror på att SQL-satserna är semantiskt fattiga och att semantiken finns i kunskapsbasen. Lexikonet för parafraseraren är gemensamt med lexikonet för analyseraren, dvs den del som gör om frågorna i naturligt språk till SQL. Slutligen matas en DCG-grammatik som körs baklänges med parseträdet och med matriserna och genererar naturligt språk.
HSQL-prototypen är implementerad mot en databas som innehåller information om olika sjukhus och deras verksamheter.
Några exempel från HSQL:
Exempel på generering av SQL från naturligt språk samt parafrasering från SQL tillbaka till naturligt språk
HSQL klarar även anafora, dvs syftning till föregående sats.
I det här exemplet sker ingen översättning av frågorna till SQL utan svaren tas direkt från databasen.
Exempel på hur HSQL behandlar frågor som det inte finns svar till i databasen. Dessa är meningslösa ur HSQL`s synpunkt men de är meningsfulla i vår värld. Av dessa exempel kan vi förstå att information saknas i databasen.
Frågan Vem behandlar X ? har två betydelser, dels att X är läkare och att X behandlar någon, men också att X är patient och behandlas av någon.
Denna tvetydighet bearbetas på följande sätt:
HSQL explicitgör den tvetydiga frågan och fyller ut med information, så att användaren får klart för sig typen av fråga hon/han ställer.
SILVIA är ett gränssnitt i naturligt språk mot en relationsdatabas som IBM utvecklar på IBM Nordiska Laboratorier, Lidingö. SILVIA genererar SQL från frågor i naturligt språk. Systemets funktion liknar det ovan beskrivna generella fråge- och svarssystemet HSQL.
En finess med SILVIA är att syntaxen och semantiken för det naturliga språket är representerat på så sätt att systemet är oberoende av språk och domän, (tillämpningsområde). Sålunda kan SILVIA lätt anpassas till ett nytt språk.
Den domänberoende kopplingen mellan databas och naturligt språk är beskriven i konceptuell modell som skapas av användaren för varje tillämpning. Den konceptuella modellen beskriver även hur informationen i databasen är organiserad.
För närvarande kan SILVIA hantera språk såsom engelska, tyska, franska, italienska och spanska. Svenska är under utveckling. En del preliminärt arbete har även gjorts för arabiska och japanska.(Bäckm 1990). SILVIA kommersiella namn var Natural Language Access. Natural Language Access säljs inte längre.
Ett expertsystem är ett datorprogam som möjliggör sökning, resonerade och slutledning inom ett domänspecifikt område.På 80-talet var det populärt med expertsystem. Expertsystemen skulle kunna ersätta nyckelpersoner inom mycket smala domäner, speciellt där det var svårt att hitta ersättare.
Expertsystem är den mest vanliga AI-tillämpningen idag. Det finns tusentals system i drift i hela världen. De flesta system ger förklaringar och svar i en kryptisk form hämtade direkt från kunskapsbasen.(Se ovan avsnittet Kunskapsrepresentation)
Pga den stora mängd expertsystem och användare av dessa är det önskvärt att förbättra förklaringarna i expertsystemen. Detta sker och kommer att ske med generering i naturligt språk.
Förklaringar i naturligt språk av slutsatserna i expertsystemen är en önskad funktion pga den stora mängd regler som finns i expertsystem, vanligtvis från 500 till 15000 regler. Eftersom en enda rekommendation från ett expertsystem kan ha utlöst upp till 15000 regler så kan det vara svårt att finna fel i systemet.
Reglerna är skrivna mer för funktionen av systemet än för att informera användaren i naturligt språk om slutsatserna.
Förklaringar i naturligt språk kan hjälpa till dels för att underhålla systemet dels för att förklara expertsystemets rekommendationer, (McKeown 1988).
MYCIN är ett av de mest ambitiösa expertsystem som har utvecklats och ansågs ha ett bra användargränssnitt i naturligt språk, (Buchanan 1974). Systemet var ett rent forskningsprojekt vid Stanford University, USA. Det började utvecklas i mitten på 70-talet och skulle vara ett stöd för läkare vid diagnosticering av blodsjukdomar. MYCIN ger diagnos och föreskriver rätt sorts medicin och rätt dos.
Systemet fungerar enligt baklänges eller måldrivet resonerade, dvs MYCIN ställer upp en hypotes och försöker därefter bevisa den med hjälp av sina regler. Måldrivet resonerande gör att MYCIN:s förklaringar känns logiska.
MYCIN kunde ge förklaringar i naturligt språk både för sina rekommendationer och sina frågor till användaren. Detta gjordes genom parafrasering av reglerna. Förklaringarna var dock mer knutna till systemets funktionen än för att underlätta en riktig förståelse av MYCIN:s slutsdragningar.
Guidon är MYCIN:s undervisningsdel. Den skulle använda sig av MYCIN:s kunskapsbas för att undervisa studenter i blodsjukdomar.
Det visade sig att kunskapen som fanns i MYCIN var dåligt förklarad och rättfärdigad för att kunna användas för undervisning.
Reglerna i MYCIN var inte uppbyggda så att det blev en naturlig förklaringsmodell. Varje regel hade ett antal delvillkor som alla skulle uppfyllas för att regeln skulle utlösas. Dessa delvillkor behövde inte ha ett logiskt sammanhang, men fungerade korrekt för rätt diagnostisering.
Teiresias är en kunskapseditor för MYCIN. Om läkaren vill gå in i MYCIN's kunskapsbas och ändra eller lägga till nya regler så hjälper Teireisias till så att läkaren inte lägger till en felaktig regel eller en motsägande regel. Hjälpen ges i form av en intelligent dialog mellan läkare och Teireisias.
Tanken är att det inte skall vara nödvändigt att ha en kunskapsingenjör för att lägga in ny kunskap. Genereringen i naturligt språk tillåter läkaren att själv agera på sitt eget språk.
Här följer ett exempel på en dialog mellan Teireisias och en doktor som försöker lägga in ny kunskap i MYCIN eftersom han tycker att det MYCIN kommer fram till är fel.
Här vill doktorn kontrollera ovanstående slutsats och eventuellt lägga in ny kunskap. Detta gör han genom att anropa kunskapseditorn Teiresias.
Nu kommer Teiresias in:
Om doktorn hade valt 1 så hade han fått reda ut problemet med VARFÖR, (WHY) och HUR, (HOW), frågor på traditionellt expertsystemsvis. Val 2 innebär att Teiresias hjälper doktorn att hitta felet.
Experten anser att programmet skulle ha fastställt en kategori och att REGEL 184 (RULE 184) inte skule ha utlösts.
Det fanns inga regler som kunde anropas för att kunna bevisa den här kategorin. De följande (möjligt tillämpbara) reglerna blev INTE exekverade eftersom klausulen märkt [++] misslyckades:
Teiresias parsar den här regeln till sin interna representation och parafraserar därefter tillbaka den till engelska så att experten kan kontrollera den. Efter det att experten godkänt eller validerat tolkningen, så försöker Teiresias föra in den nya regeln i sin kunskapsbas.
Teiresias är ett expertsystem med regler som kan resonera om regler och objekt i MYCIN:s kunskapsbas. Det fina med Teiresias är att experten själv kan lägga in ny kunskap med hjälp av naturligt språk och att Teiresias svarar honom med expertens egen terminologi och i naturligt språk. Alla regler som läggs in, har den specifika expertens signatur. Teiresias vet hur en regel om tex bakterieinfektion ungefär skall se ut och kan påpeka det för experten, (Luger 1989).
NEOMYCIN var en uppföljare till MYCIN, där varje regels bakgrundskunskap fanns med. NEOMYCIN abstraherade även sin problemlösningskunskap i metaregler. Metaregler innebär att systemet resonerar om sina egna regler. Detta gjorde att NEOMYCIN:s förklaringar kändes naturliga.
En konceptuell modell eller informationsmodell är en formell beskrivning av en verksamhet, en databas eller ett dataprogram (Boman 1997). Denna modell görs innan man påbörjar själva programmeringen av systemet för att se om man har lyckats beskriva allt som måste finnas med samt om man har gjort det på rätt sätt. Detta steg kallas kravinsamling (requirements engineering). Ett stort problem vid konstruktion av stora datasystem är att man inte lyckats göra kravinsamlingen korrekt och när man påbörjat programmeringen upptäckt att datasystemet inte är det kunden vill ha eller att det varit många fel i det. I det skedet är det dyrt och komplicerat att ändra systemet. Därför vill man gärna göra kravinsamligen korrekt. Ett sätt att göra detta är att validera modellen, dvs att undersöka om den konceptuella modellen speglar verkligheten. Detta kan göras genom att man försöker förklara för kunden eller domänexperten i naturligt språk vad modellen beskriver och därefter kan kunden korrigera eventuella fel. Andra sätt att validera modellen är att simulera den eller kontrollera den semantiskt.
STEP/EXPRESS (STandard for the Exchange of Product model data) (Al-Timimi 1996) är en standardiserad objektmodell. STEP är en ISO standard. EXPRESS är språket som standarden uttrycks i. EXPRESS är ett statiskt Entity-Relationship modelleringsspråk (ISO 1991).STEP är framförallt utvecklad av tillverkningsindustrin för att att kunna utbyta produktdatamodeller mellan olika miljöer och plattformar, tex CAD/CAM ritningar. Ett STEP/EXPRESS schema beskriver vilka begrepp som finns och hur de skall översättas.Det som beskrivs och översätts är instanser så kallade Step Physical File (SPF). Inom varje domän inom tillverkningsindustrin har man skapat så kallade Applivation Protocols (AP). Varje AP innehåller standardisade begrepp uttrycka i STEP/EXPRESS för att användas inom domänen. Det finns tex ett AP som kallas AP214 Core Data for Automotive Design Process som används inom bilindustrin. Det finns AP:n för nästan varje typ av tillverkningsprocess tom för processindustrin och elektriska kraftverk men även integrerade kretsar.
SISU har haft två examensarbeten i området konceptuell modellering
och naturligt språk. Modellering med naturligt språk, [Dahl90].
Generering av naturligt språk från konceptuella scheman, [Wall90].
Målet med examensarbetena har varit att direkt från en beskrivning i
naturligt språk skapa en konceptuell modell,
samt att kunna parafrasera denna tillbaka till naturligt
språk. En konceptuell modell kan tex användas för att beskriva en
verksamhet eller organisationen av informationen i en databas. Systemen skall kunna
användas av experter som inte är insatta i konceptuell modellering, så
att de själva ska kunna skapa modeller av sin verksamhet. Parafraseringsdelen
skall hjälpa användaren att validera den skapade modellen. Syftet med valideringen är att kunna undersöka om modellen överenstämmer
med verkligheten. Många gånger är det så att de som skall
validera modellen ej kan syntaxen för en konceptuell modell, därför
är det mycket användbart att kunna parafrasera modellen till naturligt
språk som alla förstår. Parafraseringsdelen ska även kunna
användas av modelleringsexperter. Detta görs för att underlätta
arbetet och för att undvika felaktigheter i arbetet med konstruktionen av konceptuella
modeller. 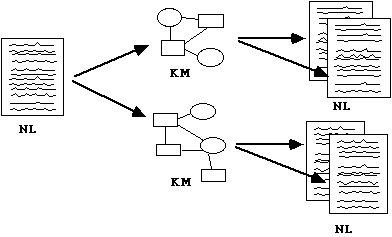
Figur 9. En tvetydig beskrivning i naturlig språk, NL, kan ge upphov till flera konceptuella modeller, KM, och en konceptuell modell kan ge upphov till flera naturligt språk beskrivningar.
Båda systemen är skrivna i Prolog och de använder sig av ett gemensamt lexikon som beskriver de olika ordens böjningsmönster.
11.3.1. Koppling mellan konceptuell modell och naturligt språk beskrivning.
Konceptuella modeller av Entity-Relationsshiptyp (ER) behandlas i [Chen83], där författaren föreslår att låta entiteter motsvaras av substantiv och relationer av verb i språket. Följer man den regeln kan man få en viss konsistens i modelleringen. Ett annat problem är att veta vad entiteterna i modellen betyder. Det måste göras en koppling med verkligheten.Detta är ett arbete som görs mellan systemeraren och domänexperten (kunden).
Till varje ny domän måste de domänspecifika orden definieras. Detta kan ske allteftersom modelleringen av domänen fortskrider. Orden lagras i en datorbaserat lexikon och används sedan vid den automatiska översättningen från naturligt språk till konceptuell modell. Samma lexikon kan sedan användas för den automatiska textbeskrivningen av modellen.
Modellering med naturligt språk har gjorts på engelska i AMADEUS av [Black87] samt på svenska i SISU-rapport nr 6, [Dahl90]. Rapporten behandlar hur ett konceptuellt schema skapas från satser på svenska. En prototyp i Prolog är implementerad som visar systemet. En parser gör en syntaxanalys av den inmatade satsen. Satsen översätts till en logisk form som representerar semantiken i satsen. Denna logiska form översätts till en del av den konceptuella modellen i form av data i Prolog, (Prologfakta). De konceptuella modeller som skapas är enligt EMOL-syntaxen, Ericsson Modelling Language.
Problemet med hur systemet tolkar tvetydiga satser är inte löst. Systemet tar den första tolkningen och översätter den till den konceptuella modellen. En möjlighet vore att den parafraserade tillbaka sina tolkningar av satsen och lät därefter användaren välja tolkning.
Påståenden i naturligt språk som härleds med hjälp av andra påståenden kommer att finnas kvar i modellen, det uppstår sk redundans. Systemet gör ingen kvalitetskontroll av det konceptuella schemat. Det finns andra verktyg utvecklade på SISU som gör detta, [Wohed88].
Generering av naturligt språk från konceptuella scheman beskrivs i SISU-rapport nr 7, (Walles 1990). Rapporten behandlar generering av naturligt språk (svenska) från konceptuella scheman. En prototyp i Prolog är implementerad som visar genereringssystemet. Det konceptuella schemat är skrivet enligt EMOL-syntaxen, Ericsson Modelling Language, och representerade som Prologfakta. Syftet med genereringssystemet är att kunna validera den konceptuella modellen mot verkligheten. Valideringen görs genom att kunna läsa i naturligt språk om alla objekt och entiteter i det konceptuella schemat.
Det lexikon som skapats av (Dahl 1990), (se föregående avsnitt), för att modellera med naturligt språk har använts av genereringssystemet för att skapa de korrekta ändelserna på de genererade orden.
Textgenereringsgrammatiken för att syntaktiskt korrekt beskriva den konceptuella modellen i naturligt språk är generell och behöver inte skrivas om för nya domäner. Genereringen görs utan att använda sig av någon logikrepresentation mellan det konceptuella schemat och det naturliga språket. Det är också möjligt att välja vilka objekt som skall beskrivas.
I en avhandling av Dalianis (Dalianis 1996a) studeras hela problematiken kring
generering av naturligt språk från formella specifikationer. Genereringen
görs med syftet att validera den den formella modellen. Det som studeras speciellt
är genereringen av koordinerade och elliptiska
satser, sk aggregering.
Se även Dalianis (1999c) och VOLVEX
projektet som beskriver automatöversättningen av STEP AP 214 Core
Data for Automotive Design Process som används inom bilindustrin till engelska
för att kunna validera STEP modellen.
VINST står för VIsual and Natural language Specification Tool, (Bretan 1993, Dalianis 1995b). VINST är en prototyp utvecklad av Ericsson för att specificera funktionaliteten för telefonitjänster. Gränsnittet bygger på att man matar in naturligt språk påståenden till systemet men också bilder på telefoner och linjer och på så sätt kan man uttöka kunskapsbasen men också och exekvera specifikationen eller ställa frågor till den.
Två andra typer av tillämpningar av textgenerering är sammanställningar och rapporter från en mängd rådata och automatisk dokumentskrivning från formella specifikationer.
Expertsystem kräver ofta långa inmatningar av data från en användare och att denne därefter tolkar de kryptiska förklaringarna från systemet, men det finns också expertsystem som får indata från sensorer, givare, satelliter eller dylikt och rapporterar till användaren i naturligt språk direkt. Ett antal sådana system har utvecklats på COGENTEX, Canada bla ANA, FRANA, RAREAS, RAREAS-II, FOG-89 samt GOSSIP.(Cargano 1989, Kittridge 1989, Bourbeau 1990).
Att just Kanada är framstående inom textgenerering beror på att det i landet finns två officiella språk: engelska och franska. För att undvika språkstrider så måste språken ha likvärdig status. Detta kan bara uppnås genom att skriva alla rapporter på båda språken samtidigt. Det går inte att skriva en rapport först och sedan översätta den till det andra språket eftersom det första språket får då en fördel eller ett övertag. För att undvika detta används språkoberoende data eller information som indata till ett textgenereringssystem som skapar rapporten på båda språken direkt.
Exempel på textgenereringssystem:
Systemen fungerar genom att ett expertsystem är "front-end", dvs tar hand om inkommande rådata och tolkar dessa. Från tolkningen skapar en textplanerare en språkoberoende representation. Från representationen byggs ett hierarkiskt topik/kommentar-träd upp. Trädet traverseras, (söks igenom) top-down för att linearisera ordningen på satserna. Detta görs bl a enligt det retoriska mönstret att attributen till objekten skall beskrivas från det generella till det speciella (Brown 1987). Från det färdiga trädet genereras de olika satserna i språken med hjälp av en satsgenerator, som i princip består av en ytgrammatik.
Fördelarna med textgenerering framför maskinöversättning är att textgenerering är:
Tyvärr är det så att bara en liten del av alla typer av rådata passar för textgenerering. Textgenerering från rådata kommer bara att användas där indata är för varierande för att människa skall klara av att sammanställa en text på en rimlig tid.
Här följer ett exempel på körning med operativsystemsrapporter från GOSSIP från rådata till text. Systemet skall kunna användas av en icke datorkunnnig vakt på nätterna, för att han skall kunna bevaka datorn och förstå vad som händer.
Indata till GOSSIP:
Utdata från GOSSIP:
Vi ser här den informativa beskrivningen i naturligt språk från rådata från en dator. Texten känns mer överskådlig än rådatat genom att GOSSIP har dragit ut alla relevanta data från rådatat och presenterat det på ett strukturerat vis. Den beskriver sammanhangen från det generella till speciella. Från hela datorsystemet till de enskilda programmen och användarna. Den strukturerade beskrivningen i naturligt språk är bättre anpassad för människor än en mängd ostrukturerad rådata.
DOCSY är ett automatiskt dokumentskrivningssystem, (Andersen 1989). Den grundläggande idén är att från en formell modell av det system som skall beskrivas och en mall för hur dokumentet skall se ut, generera manualen automatiskt. Idén med systemet är att eliminera felkällorna vid skrivandet av tekniska manualer som beskriver ett komplext system.
Första steget i genereringen av manualen är att besluta hur mycket information som skall inkluderas i dokumentet. Detta görs med hjälp av dokumentmallen.
Andra steget i genereringen är att det görs en diskursanalys på innehållet som innebär två saker: Dels att kontrollera om den extraherade informationen är tillräcklig för att fullfölja målet med texten och dels att organisera informationen så det blir en koherent text. Informationen organiseras med hjälp av mallen för hur ett dokument skall se, så att det blir en koherent text. Resultatet av diskursanalysen representeras som en ordnad sekvens av konceptuella grafer.
Tredje steget i genereringen består i att från de konceptuella graferna generera naturligt språk med hjälp av en ytgenerator. Ytgeneratorn introducerar bla anafora relationer, syftningar, i texten.
Systemet finns implementerat i en tillämpning som genererar ett dokument som beskriver styrningen av en kraftstation på ett helt automatiserat fartyg.
Ett annat liknade system är TECHDOC (Rösner 1992), syftet med
TECHDOC är att ta fram ett automatiskt genereringssystem för bilmanualer
på flera språk. TECHDOC bygger på RST.
Automatisk textsammanfattning är tekniken
där en text automatisk sammanfattas till en kortare text. Enligt (Hovy 1997)
finns det två sätt att se på textsammanfattning antingen som textextrahering
eller textabstrahering. Textextraktion innebär att delar av texten extraheras
mha statistiska eller heuristiska metoder och dessa delar sammanställs till
en ny kortare text.. Textabstrahering innebär att den ursprungliga texten analyseras
mha datalingvistiska metoder, texten analyseras semantiskt och därefter genereras
den.
enligt teknikerna beskrivna i Kap
10 Naturligt språkförståelse och Kap
9. Textgenereringsmetodik.
När automatisk textsammanfattning skall göras måste följande frågeställningar besvaras: Vad handlar texten om? Vilka delar (satser) av en text är viktiga? Vad vill läsaren veta? Är de första meningarna i text viktigare än de sista. etc.
En automatisk textsammanfattare (textextraherare) måste först förstå
vad texten handlar om, detta kan göras genom att hitta nyckelord. Nyckelord
kan finnas i titeln på texten. De kan förekomma flera gånger i texten.
För att finna nyckelord kan man använda ett lexikon med betydelsebärande
ord. Dessa är oftast substantiv, adjektiv eller adverb.
Med hjälp av nyckelorden kan de viktigaste meningarna väljas ut. Viktiga
meningar kan tex vara de som kommer först i texten och där även nyckelord
förekommer och sedan sätts de utvalda meningarna ihop till en ny sammanfattad
text, se (Dalianis
1999c) för en beskrivning av tekniken samt SweSum
för att testa en textsammanfattare för svensk nyhetstext.
Textsammanfattning växer i betydelse i samband med att mycket information skall sökas och filtreras och presenteras för en användare, tex på Internet.
Intelligent Computer Aided Instruction, ICAI, intelligent dator instruktion och Tutorial Systems, undervisningssystem är två närliggande begrepp inom Artificiell Intelligens.
Exempel på detta är dels kritiserande system som ger konstruktiv kritik, dels undervisningsystem för naturliga språk mha naturligt språk.
Ett kritiserande system CRIME, CRItiquing in MEdicine, har utvecklats vid Linköpings universitet av I. Rankin, (Rankin 1989). Domänen är den medicinska och CRIME ska kritisera behandling av urinvägsinfektioner. CRIME fungerar på så sätt att läkaren får ge ett behandlingsförslag som indata. Därefter analyserar systemet behandlingen och kommer med konstruktiv kritik i naturligt språk av behandlingsförslaget. Tanken är att läkaren inte skall känna sig styrd av expertsystemet utan det skall vara ett verktyg som validerar hans/hennes lösning på ett problem.
CRIME skall bli mer generellt så att det kan byta domän utan att hela systemet behöver skriva som och därför är Rankin tvungen att använda sig av Rhetorical Structure Theory, (se RST) som textgenereringsteknik samt speciella scheman som bygger upp resonemangen.
Det finns fem scheman definierade:
Begreppen kärna och satellit beskrivs närmare i underkapitlet Diskursstrategier i delen om RST.
Med hjälp av användarens lösningsförslag får systemet även en idé om vilken nivå användaren befinner sig på. Denna kunskap används sedan av systemet vid textgenereringen.
Ett system för undervisning i franska har utvecklats av Michael Zock på LIMSI, Language and Cognition i Frankrike. Systemet är på engelska och går ut på att användaren får välja olika lingvistiska primitiv eller grundbegrepp. Från dessa primitiver bygger systemet upp en meningsrepresentation som följer Sowas konceptuella grafer, (Sowa 1984). Från det konceptuella grafen genererar systemet den underliggande satsen på franska. Systemet kan generera parafraser på samma mening, d v s olika sätt att säga samma sak.
Användaren kan också förändra satsen genom att göra den:
Systemets mål är att användaren genom empiriska försök ska lära sig kopplingen mellan syntax och semantik.
Figur 10.
Maskinöversättning, d v s att låta datorn översätta mellan två språk, är en av de äldsta datortillämpningarna med rötter i 50-talets USA. I det kalla krigets värld skulle det i väst översättas från ryska till engelska och i Sovjetunionen från engelska till ryska. Tanken var att motståndarens rapporter och vetenskapliga artiklar skulle råöversättas för att forskarna skulle kunna se om artikeln var intressant och först då kosta på den en riktig översättning.
En önskedröm i maskinöversättningssammanhang är att finna den fulländade språkoberoende kunskapsrepresentationen, det sk interlinguat, mellan språken, d v s länken mellan språken. Idén är att använda sig av ett interlingua för att korrekt representera en sats eller text. Vidare önskas att med en knapptryckning kunna generera från interlinguat, till vilket eller vilka språk som helst, en sats eller text. En sats eller text med en helt korrekt semantik och syntax.
11.6.1. SYSTRAN
SYSTRAN är ett maskinöversättningsystem utvecklat på 60-talet
i USA. Idag finns den i ett företag kallat Babelfish.
SYSTRAN finns både som ett lokalt program men även webbaserat maskinöversättningsystem
som översätter webbsidor till och från ett antal europeiska språk
(dock ej svenska). Testa SYSTRAN
Maskinöversättningssystemet gör med hjälp av en grammatik en syntaktisk och semantisk analys på källspråkssatsen och ett syntaktiskt och semantiskt träd byggs upp.
S k transferregler bestämmer vilka transformationer som skall göras på detta träd för att det skall anpassas till målspråket, den s k transfermetoden. Från det nya trädet genereras själva målspråkssatsen med hjälp av en grammatik.
För att göra ett bra maskinöversättningssystem är det nödvändigt att systemet innehåller tillräcklig domänkunskap. Samtidigt måste texten naturligtvis också handla om samma begränsade domän.
En fråga är om tvetydigheterna skall vara kvar vid översättningen. Gäller det tekniska rapporter skall inga tvetydigheter vara kvar, medan i prosa skall de vara kvar, om nu prosa någonsin kommer att maskinöversättas.
Ett typiskt traditionellt översättningssystem är: SHALT, System for Human-Assisted Language Translation från IBM Tokyo Research Laboratory, Tokyo, Japan, (Tsutsumi 1989).
SHALT:s funktioner är:
Grammatiken är skriven i Programming Language for Natural Language Processing, PLNLP. PLNLP har ca 200 grammatikregler och 100.000 ord i lexikonet. I SHALT finns det totalt 8000 användardefinierade termer, 20.000 tekniska termer och 60.000 bastermer.
En översättning i SHALT går till på följande sätt:
En parsning görs med en bottom-up och parallell parser. På det resulterande syntaxträdet görs en två-stegs transfer. Först gör 500 transferregler om det engelska syntaxträdet till ett mer japanskliknande träd. Därefter gör 300 konversionsregler lokala och lexikala transfer på trädet. Efter detta appliceras 900 japanska generationsregler på det transformerade syntaxträdet och man får ut en japansk sats.
Denna sats postediteras av en översättare, dvs läses och rättas.
SHALT har hittills översatt 47 IBM manualer på totalt ca 6000 sidor till japanska. Av dessa har 10 manualer gått ut till kunder. På titelssidan på varje manual står: Denna manual är maskinöversatt. Översättarens produktivitet har visat sig öka med 1.5 till 3 gånger. Målet är att inom fem år göra 100% av alla översättningar av interna publikationer inom IBM i Japan med maskinöversättningssystem.
En ny intressant ansats till maskinöversättning är den statistiska. Den mest kända är den som är gjord på IBM Yorktown Heights, New York,(Brown 1989). Projektet startade 1978 och tanken var att försöka göra maskinöversättning med metoder från talteknologin. En av metoderna i talforskningen är att känna igen talade ord med statistiska metoder. Problemet med att använda metoden i maskinöversättning är att det inte är känt i vilken ordning målorden skall genereras.
För att kunna göra statistisk maskinöversättning måste systemet läras upp på vad som är korrekta satser i de två språken och vilka ord som motsvarar varandra i de två språken ett lexikon. För detta behövs en mycket stor mängd naturligt förekommande texter på båda språken. Dessa texter fanns i maskinläsbar form i Kanada och kallades för Hansarddata, efter den förläggare som publicerade brittiska parlamentsdebatter i början på 1800-talet.
Hansarddata
Allt som sägs i det kanadensiska parlamententet måste enligt kanadensisk lag översättas till de båda språken engelska och franska. Dessa rapporter finnas lagrade på data, 98 miljoner franska ord och deras ekvivalens på engelska. Ett lexikon på 82.000 franska ord och 60.000 engelska ord (Engelska språket använder färre ord än franska språket). Detta gör 2,8 miljoner ordpar och medianlängden på en sats är 22 ord.
Bag translation är en term som nämns. I Bag translation görs ingen översättning utan bara en rekonstruktion av en sats efter det att orden i satsen blandats slumpvis.
Orden i en sats blandas och läggs i en påse, som skakas om, d v s orden blandas slumpvis. Därefter försöker man rekonstruera den ursprungliga satsen. Ju längre en sats är desto svårare är det att få en korrekt sats tillbaka. I Bag Translation återfås kortare än 10 ords satser till 63% helt korrekt och till 84% semantisk helt korrekt. Detta endast med slumpen ! Detta visade att det borde vara möjligt att översätta bara man styrde slumpen med lite statistiskt underlag, dvs statistisk översättning.
De tre parametrarna i den statistiska maskinöversättningsmodellen är:
1) Längdfördelningen, längden av engelska ord.
2) Distortionssannolikheten, positionen av ett franskt ord i en sats beroende på positionen av ett engelskt ord i en annan sats och längden av ett franskt ord.
3) Översättningssannolikheten, att ett franskt ord skall översättas till ett engelskt beroende på ett engelskt ord.
Med Hansarddatat skulle systemet läras upp på korrekta texter. Detta tog totalt 150 CPU-timmar på en IBM stordator. (CPU-timmar = timmar processorn arbetar)
Ett experiment:
De 1000 vanligaste förkommande orden i engelska valdes ut och de 1700 mest förekommande orden i franska. 73 satser kortare än 10 ord, översattes till franska. Av dessa satser blev 5% exakt som Hansard versionen och 48% semantiskt korrekta !!! Dessa siffror är bra med tanke på den enkla översättningsmodellen. Målet är nu att gå vidare och förbättra översättningsmodellen och på så sätt få bättre resultat. Idén i textgenereringen är att med hjälp av statistiska metoder undersöka vilken den vanligaste formen av texter är och därefter få datorn att lära sig det.
Två exempel:
Ett exempel där det blev en exakt översättning jämfört med det upplärande Hansard exemplet.
Ett exempel där det blev en semantiskt korrekt översättning jämfört med det upplärande Hansard exemplet.
Hearsay, ett talförståelseprogram, som började utvecklas 1966 och gör en transformering av en talad sats till en skriven text. Målet med Hearsay var att det skulle ingå i ett gränssnitt i naturligt språk mot en databas med datavetenskapliga artiklar. Hearsay arbetar enligt blackboardprincipen som innebär att flera små system gör en analys av indata. Systemen har alla tillgång till varandras resultat. Analyserna som görs i Hearsay är fonetiska, syntaktiska, semantiska, och lexikala analyser. Därefter får alla dessa analysresultat transformeras till en skriven text. Hearsay hade ett ordförråd på c:a 1000 ord. Dessa talade 1000 ord är fortfarande en övre gräns på vad en dator klarar av förstå, men endast då med träning på att känna igen en specifik användares röst. För ett mindre antal ord än 1000 ord är systemen mer oberoende av talaren. Ett av de svåra problemen med talförståelse beror bl a på att att det är svårt att ur talljudet urskilja var enstaka ord börjar och slutar.
Textgenereringsområdet har expanderat mycket och det intellektuella klimatet bland forskargrupperna visar samma engagemang som hos naturligtspråkförståelse för 15 års sedan. Detta är mycket lovande med tanke på hur mycket som har uträttats inom naturligtspråkförståelse. De flesta datorsystem som kommer att utvecklas i framtiden kommer att ha någon form av textgenereringsmodul.
Programmering och styrning av datorerna kommer att ske på en högre nivå och då med naturligt språk som styr- och kommandospråk. Detta kommer att ske därför att folk kommer att byta jobb oftare och för att kunna använda sig av de olika datorsystemen kommer man vara tvungen att ha ett standardspråk, nämligen naturligt språk. Äldre datorsystem kommer att fräschas upp med ett användaranpassat gränssnitt. I projekten där dessa system utvecklas kommer fler vetenskaper att tas i bruk än idag. Det kommer att finnas psykologer, filosofer, logiker, beteendevetare, lingvister och datavetare i utvecklingslagen. Även slutanvändarna av olika system kommer att få en större roll i utvecklingsarbetet.
Datorerna kommer i framtiden att göra en större del av vårt intellektuella arbete. Därför kommer de att vara tvungna att rapportera om detta till oss. Rapporterna kommer att genereras dels från rådata men de kommer också att vara sammanfattningar från större existerande rapporter. Bruksanvisningar och manualer kommer att genereras direkt från specifikationer till olika språk. Det kommer att finnas rapporter som både människor och datorer författat om vartannat. Människorna kommer att skriva på sitt modersmål och därefter kommer texten att översättas till målspråket av en dator.
Många lekmän kommer att behöva veta mer om de komplicerade systemen de arbetar med. Systemen är ofta beskrivna i någon formell specifikation. Användaren kommer då att kunna få en naturligtspråkbeskrivning på systemet. Detta kommer att innebära att hon/han inte behöver lägga ner så mycket tid på att lära sig systemet utan kan istället arbeta effektivare.
Datorerna kommer att bli medvetna och skapa sig en modell om hur vi är som datoranvändare genom vårt sätt att arbeta med datorsystemet och och genom vår kunskap om datorsystemet och domänen vi arbetar med. Datorerna kommer med hjälp av användarmodellen att anpassa sig till vårt sätt att arbeta och därmed hjälpa oss.
Det kommer att finnas många olika typer av naturligtspråkgränssnitt i framtidens datorsystem och då i kombination med grafisk teknik. Grafik kommer naturligtvis att ha sin givna plats men naturligt språk är ändå det överlägsna kommunikationsmediet när det gäller att uttrycka tankar, åsikter och idéer. Naturligt språk är verktyget där det finns möjligheter att abstrahera och förklara invecklade resonemang.
Kommunikation i naturligt språk med datorerna kommer att ske med text men naturligtvis också med röststyrning och syntetiskt tal.
En framtidshypotes ges av (Kowalski 1988). Hypotesen är att en hacker drar sig för att lura en person framför att lura en dator. För att skydda datasystemen från "hackers", så kan man tänka sig att ha ett textgenereringssystem som vid inloggning till systemet personligen hälsar på användaren. Systemet för en dialog med hackern. Denne känner sig nervös och eftersom hon/han inte vet om det är en operatör eller ett textgenereringssystem. Om denna hacker fortsätter att försöka logga in, går en riktig operatör in och tar över. Med detta system kan ett stort antal terminaler bevakas.
Ett annat intressant område är maskinöversättning. Vid internationella telefonsamtal kommer t ex automatisk simultantolkning att bli möjlig. Detta innebär att den som talar kommer att uppleva att kontrahenten talar samma språk som han/hon, (Miike).
Inom EU går en mycket stor del av den administrativa budgeten åt till för att översätta alla dokument och handlingar som framställs mellan de tio EU-språken. Därför har det tidigare inom EG (före EU) drivits ett stort maskinöversättningsprojekt som hette EUROTRA. Man hoppades med detta system automatiskt översätta alla dokument mellan de tio EU-språken och på så sätt spara in stora summor pengar. Minsta lilla ökning av översättningshastigheten kommer att ge stora vinster.
Ett av de stora problemen med gränssnitt i naturligt språk är domänen. Problemen med gränssnitten är att de anpassas till en viss domän och skulle de sedan få en fråga som ligger utanför domänen så kan de ingenting. Dessa begränsningar kommer att finnas kvar så länge som det inte är möjligt att lära ett system ny information på ett snabbt och effektivt sätt.
Domänproblemet kommer kanske att lösas om datorn kan lära sig ny information effektivt utan att någon människa behöver assistera. Ett metod är den statistiska där ett massivt antal exempel skulle kunna lära datorn ny kunskap.
Aggregering, Aggregering är processen som eliminerar redundanser i diskurserna under naturligt språkgenerering utan att förlora någon information. Aggregering, vilken också kallas ellipsis och/eller samordning (koordinering) i lingvistisk analys, gör texten mer flytande och lättläst.
Anafora, syftning till föregående sats i en text.
Användarmodell, en modell av användaren och dennes kunskaper som datorn har för att kunna generera rätt sorts text till varje användare.
Artificiell Intelligens, AI, forskningsområdet där man strävar efter att i datorer efterlikna människans intelligenta resonerande, problemlösande och beteende. Området är en tvärvetenskap mellan datorvetenskap, filosofi, logik, lingvistik och psykologi.
Artificiella språk, även kallade formella språk, är av människan uppfunna språk, som logik, matematik, formell specifikation eller programmeringsspråk. (Se även Naturliga språk).
ATN-grammatik, Augmented Transition Network, grammatik-formalism från 1970.
Axiommängd, ett antal grundsatser inom logik, som alltid är sanna.
Bottom up parsning, en parsning som genomförs från orden till satsen.
Canned text, en text redan förutbestämd vid programmeringstillfället.
Chart parsning, en parsning som genomförs så att ingen del görs i onödan. Vilket uppnås genom att parsningsvägen sparas i varje del av parsningen.
DCG, Definite Clause Grammar, grammatikformalism sprungen ur Prolog, de flesta Prolog tolkar har en mekanism som översätter DCG till ren Prolog som går att exekvera. DCG är mycket lätt att använda, att skriva både parsningsgrammatiker och genereringsgrammatiker.
Diskurs, en talad eller skriven text, en diskurs anses bestå av ett antal koherenta satser.
Djupgenerering, generering av en text och satsplan från något ostrukturerat. Text och satsplan innehåller lämpliga syntaktiska strukturer för en ytgenerator.
Domänkunskap, kunskap inom ett avgränsat område.
Ellipsis, (grek. betyder fattas, utelämnade) utelämnade av ett eller flera lexikala objekt i en sats, men bibehållande av information, tex Johan sprang efter bollen, och Lisa också.
Expertsystem, ett datorprogam som möjliggör sökning, resonerade och slutledning inom ett domänspecifikt område.På 80-talet var det populärt med expertsystem. Expertsystemen skulle kunna ersätta nyckelpersoner inom mycket smala domäner, speciellt där det var svårt att hitta ersättare.
Formellt språk eller notation, se artificiellt språk.
Fokus, är det centrala i en diskurs. Fokus är det som betonas eller som skall framföras i diskursen.
Frames, kunskapsrepresentation uppfunnen av Minsky 1975.
Generering, datorn genererar en naturligt språk text från något formellt språk.
Grammatik, syntaxregler för ett språk
Grammatik, Reguljär, ett mycket enkelt språk kan beskrivas i denna grammatik dock ej programmeringsspråk.
Grammatik, Kontextfri, Programmeringsspråk och begränsade eller avskalade naturliga språk kan beskrivas i CFG
Grammatik, Kontextsensitiv,
Naturliga språk kan beskrivas i en sådan grammatik.
Index, ett antal ord som är signifikanta för
ett dokument, se även nyckelord.
Innehållsval, på grundval av en användares fråga väljer man ut vad som skall sägas av allt som kan tänkas sägas. Frågan styr innehållet i den genererade texten.
Interlingua, latin, betyder "mellan språken", dvs ett språk mellan språk, ett språkoberoende språk för att representera betydelsen av det sagda.
Kunskapsrepresentation, hur man representerar kunskap i en formell notation
Kunskapseditor, ett verktyg för att förändra regler och behålla konsistensen i ett expertsystem.
Koherent, sammanhängande, följdriktig, logiskt konsekvent.
Kontext, omgivning, sammanhang.
Konceptuell modell, beskriver en domän med relationer mellan objekt, samt objektens attribut. Används i första hand för databasmodellering eller affärs- eller verksamhetsmodelleing.
Koordinering eller samordning, koordinering utelämnar reduntanta lexikala objekt men bibehåller informationen. tex Johan och Lisa sprang efter bollen. se även ellipsis och aggregering.
Lambdakalkyl, en matematisk teori uppfunnet av Church på 1940-talet, som bla. beskriver hur det är möjligt att separera en funktionsdefinition från funktionsnamnet samt hur binda variabler till värden. Matematiken kan beskrivas som funktioner.
Lexikon, (efter grek. lexi som betyder ord), ordlista, beskriver orden i ett språk och ordens böjningsmönster.
Logik, grek, förnuft, eller läran om resonerande och slutledning.
Maskinöversättning, låta en dator översätta från ett naturligt språk till ett annat.
Modallogik, utvidgning av predikatlogiken för att kunna behandla modaliteter i språket. Där de modala verben nödvändig, möjlig, kontingent osv är en delmängd av.
Montaguegrammatik, en semantisk teori för att beskriva naturligt språk, uppfunnet i slutet av 60-talet och i början av 70-talet av R.Montague. Till varje syntaktisk regel skall det finnas en semantisk regel. Det skall vara ett ett-till-ett förhållande mellan syntaktiska och semantiska regler.
Möjligvärldssemantik, en semantik där tolkningen kräver att möjliga världar införs. En möjlig värld är ett tillstånd vilket kan vara eller får vara möjlig men kanske inte är det just nu. En tolkning av en sats finns i form av ett sanningsvärde enligt en av dessa världar.
Mönstermatchning, att kunna känna igen en struktur, om en struktur känns igen så matchas det. Detta innebär att en hela strukturen eller den del som matchas plockas upp (unifiering). Prolog arbetar på detta sätt.
Mängdlära, en teori som konstruerar tal med hjälp av mängdbegreppet. Det mesta av matematikens slutsatser kan bevisas mha av mängdlära.
Naturliga språk, (Natural Language), NL, de språk människor använder för att kommunicera, samt ett forskningsområde inom Artificiell Intelligens.(se även Artificiella språk).
Naturligt språk gränssnitt,
gränssnitt som möjliggör kommunikation i naturligt språk mellan
dator och människa.
Nyckelord, betydelsebärande ord som beskriver
ett dokument. Oftast substantiv, adjektiv eller adverb, se även index.
Ontologi, (efter grek. on som betyder varat eller varande), inom AI betyder ontologi en hierarkisk organiserad struktur eller taxonomi med begrepp gärna innefattande från mycket generella till specifika begrepp.
Parafrasering, generering av en redan inmatad sats för att kontrollera att den har blivit korrekt förstådd av en datorn. Datorns tolkning av en inmatad sats.
Parsa, att i en dator utföra en syntaxanalys av sats med hjälp av en grammatik och ett program.
Parser, datorprogram för att göra syntaxanalys av sats i ett språk,
Predikatlogik , formellt språk för att representera naturligt språk, uppfunnet av den tyske filosofen Gottlob Frege på 1800-talet.
Prolog, PROgramming in LOGic, PROgrammering i LOGik, programmeringsspråk för logikprogrammering uppfunnet i början av 1970-talet. Prolog fungerar som en teorembevisare.
Posteditera, efter en maskinöversättning går den mänskliga översättaren in i texten och rättar de fel datorn har gjort i översättningen.
Retorik, vetenskapen om vältaligheten.
Sats, ett uttryck i naturligt språk.
Satsplan, en plan på hur en sats skall se ut. En satsplan kan innehålla information om tex syntaktisk struktur, aggregering och satslängd.
Schema, i textgenereringssammanhang, en sorts textgrammatik som beskriver hur diskursstrategin skall vara i vilken ordning satser skall komma och hur de skall se ut.
Situationssemantik, semantisk teori för att beskriva naturligt språk. Teorin beskrivs för första gången i boken Situations and Attitudes av Barwise & Perry, som kom ut i början av 80 talet.
Situationsschema, Situationssemantikens formalism där all information om situationskontexten för en sats finns samlad.
Semantik, grek, betyder mening, betydelse; betydelsen av ord och satser i ett sammanhang.
Semantiska nät, kunskapsrepresentation i graf-form
Syntax, grek.betyder ordning; regler för ordens sammansättning till satser.
Syntaxträd, resultatet av en syntaxanalys.
Scripts, sätt att representera kunskap om olika situationer uppfunnen av Schank 1977.
SQL, Structured Query Language, ett formellt frågespråk för databaser.
Sökrymd, de tillstånd som måste passeras när sökning sker.
Taxonomi, (grek. taxi betyder ordning eller sortering och nomi betyder lag), dvs lagen om ordningen.
Teorembevisare, en automatiserad process för att kontrollera om ett teorem är en logisk konsekvens av en mängd axiom. se Prolog.
Textförståelse, att en dator förstår en text.
Textgenerering, att en dator genererar text
Textplan en plan på hur en text kan se ut. En textplan kan innehålla information om hur diskursen i en textplan ska se ut. En textplan innehåller ett antal satsplaner.
Textsträng, en följd av tecken som beskriver ett språk.
Textsammanfattning, en text sammanfattas automatiskt mha ett datorprogram till en kortare text.
Tolkning, meningstilldelning till ett formellt språk.
Top down parsning, en parsning genomförs från att bevisa satsen till de olika delarna
Topik/Kommentar, Topik är det man skall tala om, dvs ämnet man skall tala om, medan kommentar är det man talar om, dvs kommentaren till ämnet.
Tvetydighet, En naturligt språk sats kan innehålla en tvetydighet dvs ha fler än en betydelse
Typteori, teori för att bla. kunna behandla självreferens i satser, som tex satsen "Jag ljuger" eller "Denna sats är falsk". Typteori bygger på att ett högre ordningens språk måste definieras för att självreferens skall kunna beskrivas, dvs det måste finnas ett språk av en annan typ än det som självreferensen uttrycks i (Russel, Martin- Löf)
Ytgenerering eller generering av en naturlig språk sats från en syntaktisk struktur mha en (yt)grammatik och ett lexikon. se även djupgenerering.
Validera, att jämföra den formella modellen med verkligheten och se om den överstämmer
J Allen. 1987. Natural Language Understanding, Benjamin Cummings.
J. Allwood, L-G Andersson and Ö. Dahl. 1987. Logic in Linguistics, Cambridge University Press.
K. Al-Timimi and J. MacKrell. 1996. STEP: Towards Open Systems. STEP Fundamentals & Business Benefits, CIMdata.
T. Amble et al. 1990. Naturligt språk och databaser - nya vägar in i databaser, Rapport om HSQL, ett kunskapsbaserat hjälpsystem för SQL, Statskontoret.
A. Andersen et al. 1989. DOCSY- A system for automatic document writing, proceedings of Second Scandinavian Conference on Artificial Intelligence SCAI`89, Tampere, Finland.
D.E.Appelt.1985. Planning English Sentences, Cambridge University Press.
J. Barwise and J Perry. 1981. Situations and Attitudes, Journal of Philosophy 78, no 11 pp 668-692.
M. Boman, J. Bubenko, P. Johannesson and Benkt Wangler. 1997. Conceptual Modelling, Prentice Hall.
L. Bourbeau et al. 1990. Bilingual Generation of Weather forecasts in a Operations Environment, Proceedings of the 13th International Conference on Computational Linguistics, (COLING-90, Vol 3, pp 318-320.
W. J. Black. 1987. Acquisition of Conceptual Data Models from Natural Language Descriptions. In Proceedings of The Third Conference of the European Chapter of Computational Linguistics, Copenhagen, Denmark.
I. Bretan, M. Engstedt and B. Gambäck. 1995. A Multimodal Environment for Telecommunication Specifications. In Proceedings of the 1st International Conference on Recent Advances in Natural Language Processing, pp. 191-198, Tzigov Chark, Bulgaria, September.
G. Brown and G. Yule. 1987. Discourse analysis, Cambridge University Press.
P.F.Brown et al. 1989. A Statistical Approach to Machine Translation, Computer-Based Natural Language Translation, Garmisch-Partenkirschen, 8-11 Aug 1989, IBM Europe Institute.
B. G. Buchanan and E. H. Shortliffe, editors. 1984. Rule-Based Expert Systems: The MYCIN Experiments of the Stanford Heuristic Programming Project. Addison-Wesley, Reading, Massachusetts.
M. Bäckström. 1990. SILVIA: A Natural Language Inteface to Relational Databases, C-G Jansson ed., Proceedings from the Ninth Annual Workshop and Meeting of the Swedish AI-Society, SAIS-90, Stockholm.
P. P-S. Chen.1983. English Sentence Structure and Entity Relationship Diagrams, Information Sciences 29, p.p. 127-149.
W. Clocksin and C. Mellish. 1984. Programming in Prolog, Springer Verlag.
H. Dalianis.1999a. Aggregation in Natural Language Generation, Journal of Computational
Intelligence, Blackwell Publishers, Boston MA & Oxford UK, pp 384-414, Volume
15 Number 4, November .
H. Dalianis. 1999b. The VOLVEX Handbook: A General Validation Tool by Natural Language
for the STEP/EXPRESS Standard. Proceedings of the workshop `May I speak freely?''
Between templates and free choice in Natural Language Generation at the 23rd German
Annual Conference on Artificial Intelligence (KI-99), pp. 36-41, DFKI-D-99-01, Bonn,
Germany, September 14-15, 1999, HTML.
H. Dalianis. 1999c. SweSum - A text summarizer for Swedish, Nada, KTH, http://www.nada.kth.se/~hercules/Textsumsummary.html
H. Dalianis. 1998. The VINST approach:Validating and Integrating STEP AP Schemata
Using a Semi Automatic Tool. In N. Mårtensson et al (Eds). Changing the Ways
we Work - Shaping the ICT solutions for the Next Century, IOS-Press, 1998, pp. 211-220,
Proceedings of the
Conference on Integration in Manufacturing, IiM-98, in Gothenburg, Sweden, October
6-8, 1998, Abstract.
H. Dalianis. 1997a. Natural Language Aggregation and Clarification using Cue Words.
In Proceedings of the 6th European Workshop on Natural Language Generation, pp. 6-16,
March 24 - 26, 1997, Gerhard-Mercator University, Duisburg, Germany.
H. Dalianis & E. Hovy. 1997b. On Lexical Aggregation and Ordering. In Proceedings
of the 6th European Workshop on Natural Language Generation, pp. 17-27, March 24
- 26, 1997, Gerhard-Mercator University, Duisburg, Germany.
H. Dalianis. 1996a. Concise Natural Language Generation from Formal Specifications.,
Ph.D. dissertation, (Teknologie Doktorsavhandling), Department of Computer and Systems
Sciences, Royal Institute of Technology/Stockholm University, June 1996, Report Series
No. 96-008, ISSN 1101-8526, SRN SU-KTH/DSV/R--96/8--SE. Abstract.
H. Dalianis, and E.H. Hovy. 1996b. Aggregation in Natural Language Generation. Trends
in Natural Language Generation: an Artificial Intelligence Perspective, EWNLG'93,
Fourth European Workshop, G. Adorni & M. Zock (Eds), Springer Verlag Lecture
Notes in Artificial Intelligence no 1036, pp 88-105. Abstract.
H. Dalianis: 1995a. Aggregation, Formal Specification and Natural Language Generation.
In Proceedings of the NLDB'95, First International Workshop on the Applications of
Natural Language to Data Bases, pp 135-149, Versailles, France, June 28-29. Abstract.
H. Dalianis. 1995b. Aggregation in the NL-generator of the VIsual and Natural language
Specification Tool. In Proceedings of The Seventh International Conference of the
European Chapter of the Association for Computational Linguistics (EACL-95), Student
Session, pp 286-290, Dublin, Ireland, March 27-31. Abstract.
H. Dalianis. 1992. A method for validating a conceptual model by natural language
discourse generation. CAISE-92 Int. Conf. on Advanced Information Systems Engineering,
Loucopoulos P. (Ed.), Springer Verlag Lecture Notes in Computer Science, no 593,
pp.425-444. Abstract.
D. Cargano et al. 1989. Content determination and Text Structuring in Gossip, The second European Workshop on Natural Language Generation, Edinburgh 6th-8th April.
D. Chester. 1976. The Translation of Formal Proofs into English Artificial Intelligence, no 7, p. 261-278.
H. Dahlgren. 1990. Konceptuell modellering med naturligt språk SISU-rapport nr 6, 1990.
D.Dowty, R. E. Wall and S. Peters. 1987. Introduction to Montague Semantics, D.Reidel, Publishing Company.
G. Gazdar and C. Mellish. 1989. Natural Language Processing in PROLOG, Addison Wesley Publishing Company.
N. Goldman. 1975. Conceptual Generation, Conceptual Information Processing ed. R.C. Schank, North Holland Publishing Co. Amsterdam.
H.P Grice. 1975. Logic and Conversation. In Syntax and Semantics 3, Speech Acts, Cole, P. and Morgan, J.L. (eds.). New York: Academic Press pp. 41-58.
Fenstad J.E. et al. 1987. Situations, Language and Logic.
S. Haack. 1988. Philosophy of Logics, Cambridge University Press.
J.R Hobbs, 1985. On the Coherence and Structure of Dicourse, Report No CSLI-85-37, October.
J R.Hobbs. 1990. Literature and Cognition, CSLI Lecture Notes Number 21, Center for the Study of Language and Information.
W. Hodges. 1998. Logic. Penguin Books, 1988.
E. H. Hovy. 1988. Planning Coherent Multisential Text, Proceeding of the Annual Meeting of the Association of Computational Linguistics.
E. Hovy and C-Y Lin. 1997 Automated Text Summarization in SUMMARIST. in Proceedings of the Workshop of Intelligent Scalable Text Summarization, July, 1997.
ISO-1991 The EXPRESS Language Reference Manual, ISO TC184/SC4/WG5, N14, Leeds, April 29.
H. Kamp et al. 1990. From Discourse to Logic, D.Reidel Publishing Company.
D. Kohl. 1990. The General Architecture of Generation in ACORD, Proceedings of COLING 1990.
S. Kowalski. 1988. Cyber-Eye, The second Intrusion Detection Workshop.
R. Kittredge.1989. Using the Meaning Text Model for Language Generation, Computer-Based Natural Language Translation Garmisch-Partenkirschen 8-11 Aug 1989, IBM Europe Institute.
G.F.Luger and W. A Stubblefield. 1989. Artificial Intelligence and the design of Expert Systems, The Benjamin/Cummings Publishing Company Inc.
D.B Lenat et al,. 1987. On the Thresholds of Knowledge, Proceeding of IJCAI 1987.
W.C.Mann and S.A.Thompson. 1988. Rhetorical Structure Theory: Towards a Functional
Theory of Text Organization. TEXT 8(3) (243-281), 1988.
K.R McKeown. 1985a. Textgeneration: Using discourse Strategies and focus constraints
to generate natural language text, Cambridge University Press.
K. R McKeown. 1985b. Discourse Strategies for Generating Natural Language Text, Artificial Intelligence, vol 27 no 1, Sept.
K. R. McKeown. 1979. Paraphrasing Using Given and New Information in a Question-Answer System, Proceeding of the Annual Meeting of Association of Computational Linguistics.
K.McKeown and W. Swartout. 1988. Language generation and explanation, in Advances Natural Language Generation, edited by M. Zock and G. Sabah, Pinter Publishers Ltd.
S. Miike et al. Experiences with an on-Line Translating Dialogue System Research and Development Center, Toshiba Corporation.
R. Neches et al.1985. Enhanced Maintenance and Explanation of Expert Systems Through Explicit Models of Their Development, IEEE Transactions on Software Development Vol. SE-11, No 11, Nov.
C. Paris. 1985.Description Strategies for naive and expert users, Proc. of the 23rd Annual Meeting of the Association of Computational Linguistics.
C. Paris.1988. Tailoiring Object's descriptions to a User's Level of Expertize, J. of Computational Linguistics, Vol 14, No 3, Sept.
F. Pereira and S.Shieber.1987. Prolog and Natural Language Analysis, CSLI.
I. Rankin. 1989. The Deep Generation of Text in Expert Critiquing System, Lic Thesis, Dep. of Computer and Information Science, Linköping, Sweden.
D. Rösner and M. Stede. 1992. Customizing RST for the Automatic Production of Technical Manuals, in Aspects of Automated Natural Language Generation. R. Dale, E.Hovy, D. Rösner and O.Stock (Eds), Lecture Notes in Artificial Intelligence no 587, pp 199-214, Springer Verlag.
K. Severinson Eklundh. 1987. Datorstött skrivande. i Människa - Datorinteraktion vid utformning av text, bild och program, MDA-rapport 1987:15.
Shapiro. 1987. Natural Language Generation in Encyclopedia of Artificial Intelligence, John Wiley & Sons.
J. F. Sowa. 1987. Conceptual Structures, Addison-Wesley Publishing Company.
W.R Swartout. 1983. XPLAIN: a System for creating and Explaining Expert Consulting Programs, Journal of Artificial Intelligence, Vol 21, No 3 Sept.
T. Tsutsumi. 1989. The SHALT English-Japanese Translation System, Computer-Based Natural Language Translation Garmisch-Partenkirschen 8-11 Aug 1989, IBM Europe Institute.
J. Walles. 1990. Generering av naturligt språk från konceptuella modeller, SISU-rapport nr 7.
E.J. Vestre et al. 1988. Representing Direct Questions, COSMOS-Report, No.4, Oslos Universitet Mars.
R. Wohed. 1988. Diagnosis of Conceptual Schemas, SYSLAB Report No 56, March.
G.H. von Wright. 1980. Logik, Filosofi och Språk. Doxa.