Department of Computer and Systems Sciences (DSV)
The Royal Institute of Technology (KTH) and Stockholm University
Electrum 230, S-164 40 Kista, SWEDEN,
E-mail:hercules@dsv.su.se
STEP Application Protocols (APs) are often very large and complicated general descriptions of different domains mainly within the manufacturing industry. STEP AP's are expressed in the EXPRESS language which is a static modeling language of Entity-Relationship type. Users of STEP AP have often large problems to understand the whole AP and therefore they need a tool which helps them to validate the STEP AP. The tool we are proposing is a natural language English paraphraser of the STEP AP. In this handbook we are demonstrating how to automatically build a domain lexicon from one STEP AP and with this lexicon automatically translate one arbitrary STEP AP EXPRESS file into a Prolog based format to be used by a Natural Language Generator called ASTROGEN. The translation from EXPRESS format to EXPRESS Prolog format and the construction of the domain lexicon is carried out by a set of Perl programs. In this web-based handbook we are offering the reader both the source code in Perl of the translator EXPRESS to Prolog format and the automatic domain lexicon builder and the source code in Prolog of the ASTROGEN Natural Language generator.
To make STEP AP's and formal language descriptions understandable
for "naive" users one needs to paraphrase them to natural languages by
using natural language generation (NLG) techniques.
Two serious obstacles prevent the use of NLG systems for large collections. First,
the limited domain lexicon and the effort to extend it to construct the domain lexicon
is time-consuming and costly. Second, the generated text may seem too "computer-made"
and therefore boring. For example, the text below, (see Figure 1), is automatically
generated from the STEP
Application Protocol 214 (AP214), the automotive design
application protocol [Al-Timimi and MacKrell, 1996], using neither text nor sentence
planning, nor canned or example text.
| ?- question(project & project_relationship). a project is an entity and a project has an undefined_object id and a project has a string_select name and a project has a string_select description and a project has a date_time actual_start_date and a project has a date_time actual_end_date and a project has an event_or_date_select planned_start_date and a project has a product_class affected_product_class and a project has an activity work_program and a project has a period_or_date_select planned_end_date and a project_relationship is an entity and a project_relationship has a project related and a project_relationship has a project relating and a project_relationship has an undefined_object relation_type and a project_relationship has a string_select description. yes |
Figure 1. Automatically generated natural language text from AP214.
To produce even poor text like this (Figure 1) for a new
domain, the user is required to build up a lexicon of new terms, this can be a time-consuming
task. To improve the quality of such machine generated text, the user may re-use
some fragments of the STEP AP concept definitions verbatim (after all, they were
produced by humans!) and also make use of the sentence planning abilities of
the ASTROGEN
Natural Language Generator [Dalianis, 1997]
In this paper we first demonstrate the automatic construction of lexicons from the STEP AP214, as well as the acquisition of canned and example texts from its definition text files. Next, we discuss the use of the ASTROGEN Natural Language Generator [Dalianis, 1997].
STEP stands for STandard for the Exchange of Product model data, and is an ISO 10303 standard [Al-Timimi and MacKrell, 1996]. STEP has been developed by industry for the exchange of product model data between different platforms, as e.g. CAD/CAM platforms.
The STEP standard contains Application Protocols (APs) that are standardized schemata within each domain, expressing the standardized concepts. Each AP consists of two files: the formal concept definitions and the associated text definitions. APs exist in several domains, including automotive manufacturing, ship building, electrotechnical plants, and process industry. The APs are expressed in the data modeling language EXPRESS [Schenk and Wilson, 1994] EXPRESS is a static modeling language of Entity-Relationship type.
Although one can view each AP as a domain ontology, APs are not very hierarchical. Ontologies can be described as hierarchical conceptual models whose content ranges from very general concepts to very domain specific concepts. In the Artificial Intelligence community a large research effort has been devoted in ontology research, both in the construction of general purpose and domain models and in their re-use in other applications.
Several attempts have previously been made to automate the lexicon acquisition for natural language interfaces, e.g., TEAM [Grosz et al., 1987] and CLE [Alshawi, 1992]. In both TEAM and CLE, the domain users had to answer a set of question for each lexical entry and hence identify the entry. In TELL [Knight et al., 1989], another approach was made, a set of heuristics were used together with the CYC Ontology [Lenat & Guha, 1988] to identify the lexical entries. The requirements engineering community [Chen, 1983] has been identifying the relations between various entities in conceptual models and word categories.
Our view is that there is no user in a real industrial setting who is really interested in answering thousands of questions to acquire a lexicon. This argument is also reflected in [Reiter and Mellish, 1993], where the authors say that to make NLG more useful and practical, one needs to make the customization process fast and efficient. Discussing the costs and benefits for NLG, they also argue that the only way to make NLG techniques competitive is to use its advantages (flexibility in the produced texts) without its disadvantages (costly lexical acquisition and knowledge base building).
Therefore in this paper our approach is based on the assumption that the STEP schemata, per se, contain all necessary linguistic information to create a domain lexicon. The approach can be seen as something between TELL [Knight et al., 1989] and [Chen, 1983].
We also argue for the use of hybrid systems, a term coined
by Reiter [Reiter, 1995]. These are systems that use a combination of techniques
from traditional NLG systems and canned texts. Hybrid systems have turned out to
be very practical since canned texts always are available somewhere and just need
to be combined with real generated text. [Mittal and Paris, 1993] present an example
of a hybrid system using a combination of natural language generated text and examples
to make the explanation more user-friendly. A similar approach was made in [Dalianis
et al., 1997] after user studies indicating that schema information not available
in the schema is used for manual paraphrasing of schemata by domain experts.
To extract the lexicon and the canned text from the STEP files and the definition files respectively we use the Perl programming language [Wall et al., 1996], which is excellent for string processing.
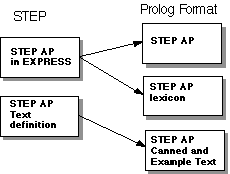
Figure 2. The different translation steps from STEP to Prolog format carried out by a set of Perl programs
Macintosh and UNIX Workstations has been used for executing the Perl programs, MacPerl 5 and Perl 5 respectively. We compiled a set of Perl programs that extracted both a domain lexicon and canned texts.
For the STEP domain in general we have an express base lexicon
[Dalianis et al., 1997] that contains all lexical terms used in the EXPRESS language.
What we need to construct is a domain lexicon for each domain or AP, as well as the
set of canned texts expressing definitions and examples (see Figure 1).
To make the translation from EXPRESS and text format to Prolog format one
need to execute the Perl program STEP_to_ASTROGEN which loads and executes
the following four other Perl programs which do the work: exp_txt_hnf.pm, express_fstruct.pm,
express_lexicon.pm and text_canned.pm.
The Perl program STEP_to_ASTROGEN takes as input all the files with
extension .exp (EXPRESS files) and .txt (text definition files) in
the same directory and process them.
For example if the original STEP EXPRESS file is called ap.exp and the
text definition file for the STEP EXPRESS file is called ap.txt then the target
files will be called ap.exp.pl, (the whole STEP AP schema in Prolog
syntax) ap.lex.pl, (the domain AP lexicon) ap.can.pl (the canned and
example texts) and ap.war. (a warning file)
Where .pl stands for Prolog file, .exp for express and .can
for canned and example text and finally .war for warnings.
Download STEP_to_ASTROGEN (5 Perl files and two Prolog files expressbaselexicon and interface, all together 7 files) in zip format and ASTROGEN NL generator (In Prolog) in zip format and read the ASTROGEN documentation (HTML). Do not forget to put all downloaded files in the same directory with the files you want to process.
Here follows two types of automatic extraction rules that are used to build a domain lexicon.
Extraction of adjectives
The lexical extraction program scans the EXPRESS files for EXPRESS attributes which are extracted as adjectives (according to [Chen, 1983]) and saved in a lexicon file with extension .exp.pl, as a Prolog DCG-clause [Clocksin and Mellish, 1984] reflecting a lexical item:
adj(sing,neut,ATTRIBUTE)-->[ATTRIBUTE].
Extraction of nouns
The lexical extraction program scans the EXPRESS files for EXPRESS entities, which are extracted as nouns (according to [Chen, 1983]) and saved in the lexicon file, with extension .exp.pl (same file as above) as a Prolog DCG-clause:
noun(sing,neut,ENTITY) --> [ENTITY].
Here follows two types of automatic extraction rules that are used to extract canned text.
Extraction of canned definition text
The canned text extraction program scans the EXPRESS definition files for definitions corresponding to a specific entity, which are saved to a file, with extension .can.pl as a Prolog fact canned_text together with the specific entity as a key:
canned_text(ENTITY,'Text that describes the entity...').
The text definition file contains textual information in
natural language (NL) form of each entity. We extract only the first sentence of
each text description since we have the impression that this gives a fair overview
description of the entity. In many cases the full text description is cumbersome.
Extraction of canned example text
The canned text extraction program scans the EXPRESS definition files for examples corresponding to a specific entity, which are saved to a file, with extension .can.pl (same file as above), as a Prolog fact canned_example together with the specific entity as a key:
canned_example(ENTITY,'Text which gives an example on the entity...').
Altogether from the STEP AP214, the automotive design application
protocol, containing 501 concepts, we created 1551 lexical objects (1291 nouns and
260 adjectives), 492 canned definition texts, and 106 canned example texts.
The ASTROGEN generator [Dalianis, 1997] is written in Prolog. ASTROGEN has its main strength in its aggregation rules, [Dalianis and Hovy, 1996], that remove redundant portions of a text without changing the content. In the ASTROGEN documentation one can read about the use of the ASTROGEN generator and also download the whole generator.
ASTROGEN takes as input a set of content-selected f-structures (an internal representation) and performs first sentence planning: it applies the aggregation rules to the f-structures, carries out pronominalization on the aggregated result, then creates a coherent discourse structure of the f-structures, and second with this as input, the surface generator then generates the syntactic surface structure and the lexical objects. Finally, the sentence transformer performs the post-processing of the text. (see Figure 3).
We have extended/customized the ASTROGEN generator with an interface and a base lexicon both written i Prolog. The purpose of the interface is to make it possible to ask questions about the Application Protocol and the base lexicon for defining specific EXPRESS reserved words.
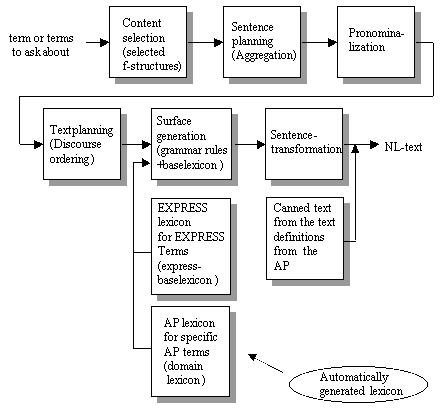
Figure 3. The ASTROGEN architecture adapted
for generation of NL from a STEP AP.
The AP lexicon is automatically generated.
Translating a whole STEP AP file to Prolog f-structures
To make use of Prolog's extremely efficient matching capability we translated the whole STEP AP (EXPRESS) file to f-structures in Prolog syntax, one side effect of the Prolog syntax was that we could use Prolog's matching capabilities to easily make content determination from the abundant knowledge base of the STEP AP.
Content selection
The interface between the user and the generator makes use of Prolog's matching capabilities. If the user asks a question that combines two concepts, Prolog will retrieve one answer that contains both concepts, effecting content selection. The aggregation mechanism of ASTROGEN will combine these two concepts into one answer if they have lexical items in common.
Pronominalization rules in ASTROGEN
The pronominalization rules are built as a separate module after the aggregation module. The pronominalization module inserts pronomina where necessary. It determines the tense and the gender of the subject from the lexicon. For illustrative purposes in the example in Figure 3, we do not use the subject and predicate aggregation rule [Dalianis and Hovy, 1996], since that would block the pronominalization rules, instead of pronominalization we will use subject and predicate aggregation.
Sentence transformation
As a final step we perform a set of sentence transformations
to blend the generated output, which consists of both generated sentences and fragments
of canned text, together. The sentence transformation rules are applied on the final
output NL string. Two main heuristics are carried out. First, each first letter of
a sentence is capitalized so the text will look more natural when displayed together
with the canned definitions and example texts. Second, the aggregated (coordinated and elipted) [Dalianis and Hovy 1996] text is post-processed
by replacing consecutive ands with commas, except for the final and. The
canned texts (and example texts) are reproduced just as they are stored in the definition
files; no sentence transformation is carried out on them.
When all the above mentioned preparations were complete, we generated concept descriptions from the STEP AP 214 in NL, using ASTROGEN. Three examples are shown in Figure 3. Each concept description contains sentences describing the supertype, subclasses and attributes of the concept (produced by ASTROGEN) and the canned definitions and when available the canned example. As can be seen from Figure 4, the generated and canned texts fit together nicely to give a fairly coherent result.
We produced descriptions for 501 concepts from the STEP AP214.
To execute the ASTROGEN Natural Language generator on the STEP AP after having translated the STEP AP to Prolog format and created the lexicon, one needs to consult in Prolog the initialisation file astrogenstep. The file astrogenstep is automatically created by the Perl programs and will contain all the new file names of the new created files. The initialisation file astrogenstep will consult the whole ASTROGEN generator and the following files: expressbaselexicon and the STEP AP lexicon, STEP AP canned texts, and the STEP AP file which now are all in Prolog format. (There might be small minor problems in consulting some of the automatically created predicates in the STEP AP, the STEP AP lexicon and the canned and example texts then one need just to comment away these particular lines by entering a "%" in the beginning of the line. These problems are due to that translator from STEP to Prolog format have some bugs. The astrogenstep initialisation file will also put some of the generation switches in certain order. (see below and ASTROGEN documentation for more details.)
:- canned_text, canned_example,clause_comma, pronoun, predicate_do.
The Prolog predicate question/1, takes as input one or more concepts delimited by "&", see figure 4 below. The question predicate matches against the Prolog database and selects the right content in form of one or more f-structures delimited by "&", the f-structures are then used to generate the appropriate NL-descptions. The question/1 predicate is connected with the paraphrase/1 predicate in the Prolog file interface.
The Prolog predicate entities/0 will give a list of all the available entities
in the STEP AP.
The Prolog predicate document/0 will give a NL description of all Entities
in the STEP AP
| ?- question(fillet). A constant_radius_fillet is a subtype of a fillet. A fillet is an entity. It is a subtype of a transition_feature. (Pron.) A Fillet is a concave circular arc transition between two intersecting Face (see 4.2.167) objects without any constraints concerning changes of the radius along the Fillet. (Canned text) yes ?- subject_pred. (Adds subject predicate aggregation) yes ?- question(project & project_relationship). A project and a project_relationship are entities. (Aggregation ) A project and a project_relationship have a string_select description.(Aggregation ) A project has a date_time actual_end_date, a date_time actual_start_date, a product_class affected_product_class, an undefined_object id, a string_select name, a period_or_date_select planned_end_date, an event_or_date_select planned_start_date and an activity work_program. (Subject predicate aggregation) A project_relationship has a project related, a project relating and an undefined_object relation_type. A Project is a unique process with a time limit, with a defined goal, with a defined budget, and with defined resources. (Canned text) A Project_relationship is a relationship between two Project (see 4.2.356) objects. EXAMPLE 174 -- For the development of a new car, a project is set up that is responsible for the development decisions as well as for the accounting of the costs. (Example text) yes ?- set(subject_pred(no)). (Removes subject predicate aggregation) yes ?- question(organization & organization_in_contract & contract & person). A contract, an organization, (Agg.+ sent. transf.) an organization_in_contract and a person are entities. A contract, an organization and a person have an undefined_object id. An organization and a person have an undefined_object name. A contract has a contracted_element_select contracted_element. It has an undefined_object ordered_price. (Pron.) It has an organization_in_contract release. " An organization has an undefined_object delivery_address. It has an undefined_object organization_type.(Pron.) It has an undefined_object postal_address. " It has an undefined_object visitor_address. " An organization_in_contract has a contract contract. It has an organization contracted_organization. " It has a string_select role_of_organization. " It has a date_and_person_or_organization signature." A person has an undefined_object address. It has a person_in_organization organization. " An Organization is a group of people involved in a particular business process. (Canned text) An Organization_in_contract is a mechanism to associate the person who is signing a contract and the organization which the person is signing for with a Contract (see 4.2.99). A Contract is a binding agreement concerning the design of Item_version (see 4.2.248) objects and/or the carrying out of Activity (see 4.2.2) objects. A Person is an individual human being who has some relationship to the product data. yes |
Figure 4. The output from of the ASTROGEN generator describing STEP AP214, Italicized comments indicate processing steps.
In this paper we describe a fast and efficient method to
build a natural language generation system for a real industrial setting. This work
has been carried out by building the lexicon and adapting the database to Prolog
and to ASTROGEN automatically from STEP APs.
The validation tool developed within the VOLVEX project was used by the ESPRIT Project
no 20496 Sedres, Systems Engineering Data Representation and Exchange Standardisation,
to translate WD3 for STEP AP233 to Natural Language.
Future work will be to adapt this generation technique to a similar domain namely
the UML Unified Modeling Language which is a new standard in software engineering.
UML is similar to EXPRESS but has dynamics.
Our plan is to integrate the results of this paper with the VINST
tool [Dalianis, 1998], in order to provide the user with
extracts of STEP Schemata translated to NL.
Future basic research will be to elaborate on the extraction of nouns from entities
and adjectives from attributes and to extend the sentence and text planner.
Acknowledgements
Great thanks to Dr Eduard Hovy and USC/Information Sciences Institute for interesting and fun discussions around automatic
integrations and to Dr.Chin-Yew
Lin and Uli Germann also at USC/Information
Sciences Institute for their help in the art of programming Perl.
I would also like to thank my sponsors Volvo Research Foundation, Volvo Educational
Foundation and Dr Pehr G Gyllenhammar Research Foundation for their support to the
VOLVEX project- Validation Of
Specifications by Natural Language Generation for VOLVO expressed in STEP/EXPRESS.
Alshawi, H. (Ed.) 1992. The Core Language Engine, MIT Press.
Al-Timimi, K. and J. MacKrell. 1996. STEP Towards Open Systems. STEP Fundamentals & Business Benefits, CIMdata.
Chen, P. P-S. 1983. English Sentence Structure and Entity Relationship Diagrams, Information Sciences 29(2), pp. 127-149.
Clocksin, W.F. and C.S. Mellish. 1984, Programming in Prolog. Springer Verlag.
Dalianis, H. and E. Hovy. 1996. Aggregation in Natural Language Generation. In Adorni, G. & Zock, M. (Eds.), Trends in Natural Language Generation: an Artificial Intelligence Perspective, EWNLG'93, Fourth European Workshop, Lecture Notes in Artificial Intelligence, No. 1036, Springer Verlag. pp. 88-105, .
Dalianis, H. 1997. ASTROGEN-Aggregated deep and Surface naTuRal language GENerator, http://www.dsv.su.se/~hercules/ASTROGEN/ASTROGEN.html
Dalianis, H, P. Johannesson and A. Hedman. 1997. Validation of STEP/EXPRESS Specifications by Automatic Natural Language Generation. In Proceedings of RANLP'97: Recent Advances in Natural Language Processing, pp. 264-269. Tzigov Chark, Bulgaria, September 11-13, 1997.
Dalianis, H. 1998. The VINST Approach:Validating and Integrating STEP AP Schemata Using a Semi Automatic Tool. In N. Mårtensson et al (Eds). Changing the Ways We WorkShaping the ICT solutions for the Next Century, IOS-Press, 1998, pp. 211220. Proceedings of the Conference on Integration in Manufacturing (IiM-98). Gothenburg, Sweden, October 68, 1998.
Grosz, B.J., D.E. Appelt, P.A. Martin, and C.N.Pereira. 1987. Team: An Experiment in the Design of Transportable Natural-Language Interfaces, J. Artificical Intelligence 32(2) pp. 173-243.
Knight, K., E. Rich and D. Wroblewski. 1989. Integrating Language Acquistion and Knowledge Acquisition. In the Proceedings of First International Workshop on Lexical Acquistion IJCAI-89.
Lenat, D. and R.V. Guha. 1988. The world according to CYC. Tech Report ACA-AI-300-88 MCC (Microelectronics and Computer Technology).
Mittal, V. and C. Paris. Automatic Documentation Generation: The Interaction of Text and Examples. Proceedings of 13th International Joint Conference on Artifical Intelligence, IJCAI-93, pp. 1158-1163.
Reiter, E. and C. Mellish. 1993. Optimizing the Costs and Benefits of Natural language Generation. Proceedings of 13th International Joint Conference on Artifical Intelligence, IJCAI-93, pp. 1164-1169.
Reiter, E. 1995. NLG vs. Template. In Proceedings of the Fifth European Workshop on Natural Language Generation, Leiden, The Netherlands.
Schenk, D. and P. Wilson 1994. Information Modeling the Express Way, Oxford University Press.
Wall, L., T. Christensen, and R.L. Schwartz. 1996. Programming
Perl. O'Reilly & Associates Inc.