Said Simple Simon to the pieman "Let me taste your ware"
Said the pieman to Simple Simon "Show me first your penny"
Said Simple Simon to the pieman "Sir, I have not any!"
and the following query q:
simple simple simon
We will calculate similarity between them using normalized similarity formula
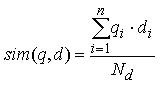
The assignment requires that we use term frequencies as weights, i.e. qi is term frequency for the ith term in the query, and di is term frequency for the ith term in the document. For the above example, the values are as follows.
Query: qsimple = 2 qsimon = 1 All other qi values are 0.
Document: dsimple = 4
dsimon = 4
dmet = 1
da = 1
dpieman = 4
dgoing = 1
dto = 4
dthe = 4
dfair = 1
dsaid = 3
dlet = 1
dme = 2dtaste = 1
dyour = 2
dware = 1
dshow = 1
dfirst = 1
dpenny = 1
dsir = 1
dI = 1
dhave = 1
dnot = 1
dany = 1
Now when we know all the qi and di values, we calculate the numerator (täljare) in the similarity formula:
qsimple · dsimple + qsimon · dsimon + qmet · dmet + qa · da + qpieman · dpieman + qgoing · dgoing + qto · dto + qthe · dthe + qfair · dfair + qsaid · dsaid + qlet · dlet + qme · dme + qtaste · dtaste + qyour · dyour + qware · dware + qshow · dshow + qfirst · dfirst + qpenny · dpenny + qsir · dsir + qI · dI + qhave · dhave + qnot · dnot + qany · dany =
2 · 4 + 1 · 4 + 0 · 1 + 0 · 1 + 0 · 4 + 0 · 1 + 0 · 4 + 0 · 4 + 0 · 1 + 0 · 3 + 0 · 1 + 0 · 2 + 0 · 1 + 0 · 2 + 0 · 1 + 0 · 1 + 0 · 1 + 0 · 1 + 0 · 1 + 0 · 1 + 0 · 1 + 0 · 1 + 0 · 1 = 12
Nd in the similarity formula is the number of words in the document. The assignment says we count stop-words as well, therefore in the above example Nd = 42.
Finally, we calculate sim(q, d) as 12/42 = 0.28571.
Assignment 2